
高性能JavaScript——第三章
DOM编程
浏览器中的DOM
尽管DOM是个与语言无关的API,他在浏览器中的接口却是用javascript实现的。浏览器中通常会把DOM和JavaScript独立实现。两个相互独立的功能只要通过接口连接,就会产生消耗。有个比喻:把DOM和JavaScript(这里指ECMAScript)各自想像为一个岛屿,他们之间用收费桥梁连接。ECMAScript每次访问DOM都要途径这座桥,并缴纳“过桥费”。访问DOM的次数越多,费用也就越高。
看看下面的例子就很明显了:
1 | console.time('dom'); |

由上图可知,访问DOM的次数越多,代码运行的速度越慢。因此,通用的经验法则是:减少DOM的次数,把运算尽量留在ECMAScript这一端处理。
节点克隆
使用DOM方法更新页面内容的另一个途径是克隆已有元素,而不是创建新元素。也就是说使用element.cloneNode()来代替document.createElement()。在大多数浏览器中节点克隆更有效率,但也不是特别明显。
HTML集合
HTML集合是包含了DOM节点引用的类数组对象。以下方法的返回值就是一个集合(HTMLCollection):
1 | document.getElementById(); |
下面的属性同样返回HTML集合:
- document.images:页面中所有img元素
- document.links:页面中所有a元素
- document.forms:页面中所有表单元素
HTML集合以一种“假定实时态”实时存在,这意味着当底层文档对象更新时,它也会自动更新。事实上,HTML集合一直与文档保持着连接,每次你需要最新的信息时,都会重复执行查询过程,哪怕只是获取集合里的元素个数(即访问集合的length属性)。这正是低效之源。
考虑下面这段代码:
1 | let allDivs = document.getElementsByTagName('div'); |
这段代码看上去只是简单地把页面中div元素的数量翻倍。它遍历现有的div元素,每次创建一个新的div并添加到body中。但事实上,这时一个死循环,因为循环的退出条件allDivs.length在每次迭代时都会增加,它反映出的是底层文档的当前状态。
像这样遍历HTML集合可能会导致错误,而且也很慢,因为每次迭代都执行查询操作。读取一个集合的length属性要比读取普通数组的length要慢很多。可以利用Array.from()方法把类数组对象转为数组。
一般来说,对于任何类型的DOM访问,需要多次访问同一个DOM属性或方法需要多次访问时,最好使用一个局部变量缓存此成员。当遍历一个集合时,第一优化原则时把集合存储在局部变量中,并且把length属性缓存在集合外。然后,使用局部变量替代这些需要多次读取的元素。
选择器API
querySelectorAll()返回值是一个静态列表。如果使用document.getElementsByClassName()等方法返回HTMLCollection,需要把它转为数组才能得到与querySelectorAll()返回值类似的静态列表。
如果需要大量组合查询,使用querySelectorAll()会更有效率。
比如,页面中有一些class为“warning”的div元素和一些class为“notice”的div元素,如果同时得到它们的列表,建议使用querySelectorAll():
let errs = document.querySelectorAll(‘div.warning, div.notice’);
如果不使用querySelectorAll,要获得相同的结果则复杂的多。其中一种做法是选择所有div元素,遍历剔除不符合条件的部分。
1 | let errs = [], |
重绘与重排
webkit内核浏览器渲染过程:
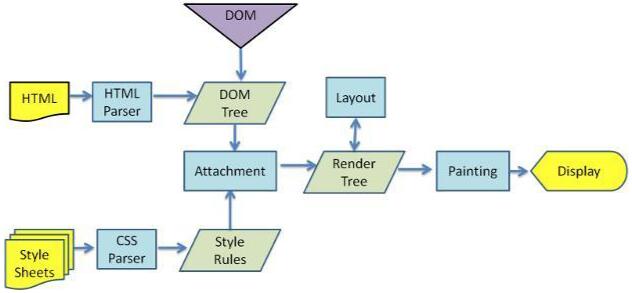
浏览器内核拿到内容以后,渲染的大致步骤可以分为:
- 解析HTML,构建DOM树
- 解析CSS,构建CSS规则树
- 合并DOM树和CSS规则树,生成render树
- 布局render树(layout/reflow),负责各元素尺寸、位置的计算
- 绘制render树(paint),绘制页面像素信息
- 浏览器将各层信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上。
当通过js动态的修改了DOM或CSS,会导致重排或者重绘。当DOM的变化影响了元素的几何属性(宽和高)——比如改变边框宽度或给段落增加文字,导致行数增加——浏览器需要重新计算元素的集合属性,同样其他元素的几何属性和位置也会因此受到影响。浏览器会使渲染树中受到影响的部分失效,并重新构造渲染树。这个过程称为“重排(reflow)”。完成重排后浏览器会重新绘制受影响的部分到屏幕中,这个过程称为“重绘(repaint)”。
并不是所有的DOM变化都会影响几何属性。例如,改变一个元素的背景色并不会影响它的宽和高。这种情况下,只会发生一次“重绘”。因为元素的布局没有改变。
重排一定导致重绘,但是重绘不一定导致重排。
重排何时发生
下列情况中会发生重排:
- 添加或删除可见的DOM元素
- 元素位置改变
- 元素尺寸改变(包括:内外边距、边框宽度、宽度、高度等属性改变)
- 内容改变,例如:文本改变或图片被另一个不同尺寸的图片代替
- 页面渲染器初始化
- 浏览器窗口尺寸改变
有些改变会触发整个页面的重排:例如,当滚动条出现时。
渲染树变化的排队与刷新
由于每次重排都会产生计算消耗,大多数浏览器通过队列化修改并批量执行来优化重排过程。然而,经常不知不觉强制刷新队列并要求计划任务立即执行。获取布局信息的操作会导致队列刷新,比如以下方法:
- offsetTop, offsetLeft, offsetWidth, offsetHeight
- scrollTop, scrollLeft, scrollWidth, scrollHeight
- clientTop, clientLeft, clientWidth, clientHeight
- getComputedStyle() (currentStyle in IE)
window.getComputedStyle() 等价于 document.defaultView.getComputedStyle()
以上属性和方法需要返回最新的布局信息,因此浏览器不得不执行渲染队列中的“待处理变化”并触发重排以返回正确的信息。在修改样式的过程中,最好避免使用上面的属性。他们会刷新队列,即使在获取最近未发生变化的或与最新改变无关的布局信息。
最小化重绘和重排
重绘和重排的代价可能非常昂贵,因此一个好的提高程序的响应速度的策略就是减少此类操作的发生,合并多次对DOM和样式的修改,然后一次处理掉。
考虑这个例子:
1 | let el = document.getElementById('mydiv'); |
示例中有三个样式属性被改动,每一个都会影响元素的几何结构。
使用cssText属性可以实现同样的效果并且效率更高:
1 | let el = document.getElementById('mydiv'); |
例子中的代码修改cssText属性并覆盖了已存在的样式信息,因此如果想保留现有样式,可以把它附加在cssText字符串的后面:
1 | el.style.cssText += '; border-left: 1px'; |
批量修改DOM
当需要对DOM元素进行一系列操作时,可以通过以下步骤来减少重绘和重排的次数:
- 使元素脱离文档流
- 对其应用多重改变
- 把元素带回文档
该过程里会触发两次重排——第一步和第三步。如果忽略这两个步骤,那么在第二步所产生的任何修改都会触发一次重排。
有三种基本方法可以使DOM脱离文档:
- 隐藏元素,应用修改,重新显示
1 | let ul = document.getElementById('mylist'); |
- 使用文档片段(document fragment)在当前DOM之外构建一个子树,再把它拷贝到文档。(推荐)
1 | const list = document.querySelector('#list'); |
- 将原始元素拷贝到一个脱离文档的节点中,修改副本,然后替换原始元素。
1 | let old = document.getElementById('mylist'); |
事件委托
当页面中存在大量元素,而且每一个都要一次或者多次绑定事件处理器(比如onclick)时,这种情况可能会影响性能。每绑定一个事件处理器都是有代价的,要么加重了页面负担,要么增加了运行期的执行时间。
一个简单而优雅的处理DOM事件的技术是事件委托。它是基于这样一个事实:时间逐层冒泡并能被父元素捕获。使用事件代理,只需要给最外层元素绑定一个处理器,就可以处理在其子元素上触发的所有事件。
每个事件都要经历3个阶段:
- 捕获
- 到达目标
- 冒泡
事件委托利用了事件冒泡,可以只使用一个事件处理程序来管理一种类型的事件。







.jpg)