
How JavaScript works - memory management + how to handle 4 common memory leaks
How JavaScript works: memory management + how to handle 4 common memory leaks
JavaScript工作原理:内存泄露 + 如何处理4中常见的内存泄露
Overview
概览
Languages, like C, have low-level memory management primitives such as malloc() and free(). These primitives are used by the developer to explicitly allocate and free memory from and to the operating system.
像C这样的语言,拥有底层内存管理原语,例如
malloc()和free()。开发人员使用这些原语显式地分配和释放操作系统中的内存。
At the same time, JavaScript allocates memory when things (objects, strings, etc.) are created and “automatically” frees it up when they are not used anymore, a process called garbage collection. This seemingly “automatical” nature of freeing up resources is a source of confusion and gives JavaScript (and other high-level-language) developers the false impression they can choose not to care about memory management. This is a big mistake.
与此同时,当创建事物(对象,字符串等)的时候,JavaScript 分配内存并且当它们不再使用的时候 “自动释放” 内存,这一过程称为内存垃圾回收。这个看起来 “自动化释放资源” 的特性是引起混乱的原因,并且给予 JavaScript(及其它高级语言)开发者一个错误的印象即他们可以选择忽略内存管理。这是一个巨大的错误。
Even when working with high-level languages, developers should have an understanding of memory management (or at least the basics). Sometimes there are issues with the automatic memory management (such as bugs or implementation limitations in the garbage collectors, etc.) which developers have to understand in order to handle them properly (or to find a proper workaround, with a minimum trade off and code debt).
即使是当使用高级语言的时候,开发者也应该要理解内存管理(或者至少是一些基础)。有时候自动化内存管理会存在一些问题(比如垃圾回收中的 bugs 或者实施的局限性等等),为了能够合理地处理内存泄漏问题(或者以最小代价和代码缺陷来寻找一个合适的方案),开发者就必须理解内存管理。
Memory life cycle
内存生命周期
No matter what programming language you’re using, memory life cycle is pretty much always the same:
不管你使用哪种编程语言,内存生命周期几乎是一样的:
Here is an overview of what happens at each step of the cycle:
以下是每一步生命周期所发生事情的一个概述:
- Allocate memory — memory is allocated by the operating system which allows your program to use it. In low-level languages (e.g. C) this is an explicit operation that you as a developer should handle. In high-level languages, however, this is taken care of for you.
- 分配内存 - 内存是由操作系统分配,这样程序就可以使用它。在底层语言(例如 C 语言),开发者可以显式地操作内存。而在高级语言中,操作系统帮你处理。
- Use memory — this is the time when your program actually makes use of the previously allocated memory. Read and write operations are taking place as you’re using the allocated variables in your code.
- 使用内存 - 这是程序实际使用之前分配的内存的阶段。当你在代码中使用已分配的变量的时候,就会发生内存读写的操作。
- Release memory — now is the time to release the entire memory that you don’t need so that it can become free and available again. As with the Allocate memory operation, this one is explicit in low-level languages.
- 释放内存 - 该阶段你可以释放你不再使用的整块内存,该内存就可以被释放且可以被再利用。和内存分配操作一样,该操作也是用底层语言显式编写的。
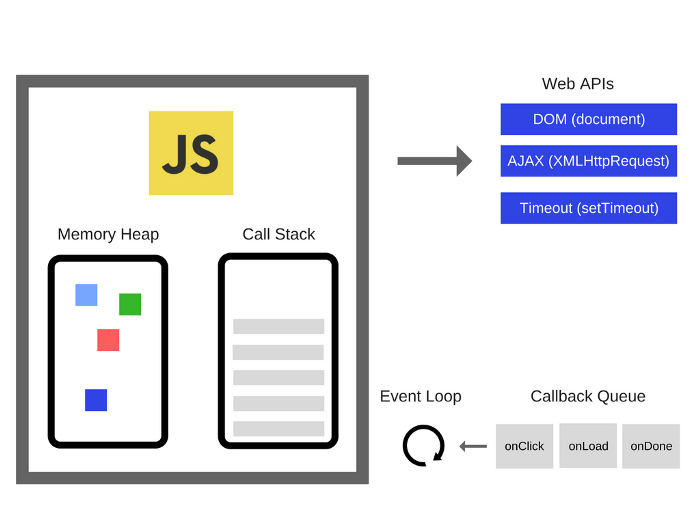
For a quick overview of the concepts of the call stack and the memory heap, you can read our first post on the topic.
为快速浏览调用堆栈和动态内存管理的概念,你可以阅读第一篇文章。
What is memory?
什么是内存
Before jumping straight to memory in JavaScript, we’ll briefly discuss what memory is in general and how it works in a nutshell.
在直接跳向 JavaScript 内存管理之前,先来简要地介绍一下内存及其工作原理。
On a hardware level, computer memory consists of a large number of
flip flops. Each flip flop contains a few transistors and is capable of storing one bit. Individual flip flops are addressable by a unique identifier, so we can read and overwrite them. Thus, conceptually, we can think of our entire computer memory as a just one giant array of bits that we can read and write.
从硬件层面看,计算机内存是由大量的 flip flops 所组成的(这里大概查了下,即大量的二进制电路所组成的)。每个 flip flop 包含少量晶体管并能够存储一个比特位。单个的 flip flops 可以通过一个唯一标识符寻址,所以就可以读和覆写它们。因此,理论上,我们可以把整个计算机内存看成是由一个巨大的比特位数组所组成的,这样就可以进行读和写。
Since as humans, we are not that good at doing all of our thinking and arithmetic in bits, we organize them into larger groups, which together can be used to represent numbers. 8 bits are called 1 byte. Beyond bytes, there are words (which are sometimes 16, sometimes 32 bits).
作为人类,我们并不擅长用位来进行所有的逻辑思考和计算,所以我们把位组织成一个更大的组,这样就可以用来表示数字。8 位称为一字节。除了字节还有字(16 或 32 位)。
A lot of things are stored in this memory:
内存中存储着很多东西:
- All variables and other data used by all programs.
- The programs’ code, including the operating system’s.
- 所有变量及所有程序使用的其他数据
- 程序代码,包括操作系统的代码
The compiler and the operating system work together to take care of most of the memory management for you, but we recommend that you take a look at what’s going on under the hood.
编译器和操作系统一起协作来为你进行内存管理,但是建议你了解一下底层是如何实现的。
When you compile your code, the compiler can examine primitive data types and calculate ahead of time how much memory they will need. The required amount is then allocated to the program in the call stack space. The space in which these variables are allocated is called the stack space because as functions get called, their memory gets added on top of the existing memory. As they terminate, they are removed in a LIFO (last-in, first-out) order. For example, consider the following declarations:
当编译代码的时候,编译器会检查原始数据类型并提前计算出程序运行所需要的内存大小。在所谓的静态堆栈空间中,所需的内存大小会被分配给程序。这些变量所分配到的内存所在的空间之所以被称为静态内存空间是因为当调用函数的时候,函数所需的内存会被添加到现存内存的顶部。当函数中断,它们被以 LIFO(后进先出) 的顺序移出内存。比如,考虑如下代码:
1 | int n; // 4 字节 |
The compiler can immediately see that the code requires 4 + 4 × 4 + 8 = 28 bytes.
编译器会立即计算出代码所需的内存:4 + 4 x 4 + 8 = 28 字节。
That’s how it works with the current sizes for integers and doubles. About 20 years ago, integers were typically 2 bytes, and double 4 bytes. Your code should never have to depend on what is at this moment the size of the basic data types.
编译器是这样处理当前整数和浮点数的大小的。大约 20 年前,整数一般是 2 字节而 浮点数是 4 字节。代码不用依赖于当前基础数据类型的字节大小。
The compiler will insert code that will interact with the operating system to request the necessary number of bytes on the stack for your variables to be stored.
编译器会插入标记,标记会和操作系统协商从堆栈中获取所需要的内存大小,以便在堆栈中存储变量。
In the example above, the compiler knows the exact memory address of each variable. In fact, whenever we write to the variable n, this gets translated into something like “memory address 4127963” internally.
在以上示例中,编译知道每个变量的准确内存地址。事实上,当你编写变量 n 的时候,会在内部把它转换为类似 “内存地址 412763” 的样子。
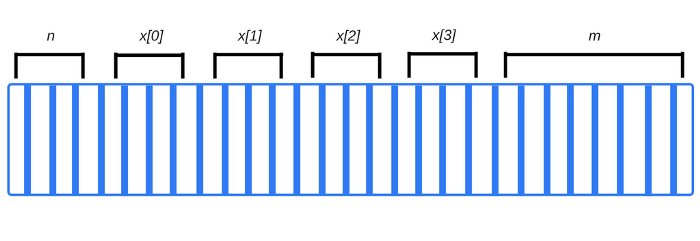
Notice that if we attempted to access x[4] here, we would have accessed the data associated with m . That’s because we’re accessing an element in the array that doesn’t exist — it’s 4 bytes further than the last actual allocated element in the array which is x[3], and may end up reading (or overwriting) some of m’s bits. This would almost certainly have very undesired consequences for the rest of the program.
注意到这里当我们试图访问
x[4]时候,将会访问到m相关的数据。这是因为我们访问了数组中不存在的数组元素-它超过了最后一个实际分配到内存的数组元素x[3]的 4 字节,并且有可能会读取(或者覆写)m的数据。这几乎可以确定会产生其它程序所预料不到的后果。
When functions call other functions, each gets its own chunk of the stack when it is called. It keeps all its local variables there, but also a program counter that remembers where in its execution it was. When the function finishes, its memory block is once again made available for other purposes.
当函数调用其它函数的时候,各个函数都会在被调用的时候取得其在堆栈中的各自分片内存地址。函数会把保存它所有的本地变量,但也会有一个程序计数器用来记住函数在其执行环境中的地址。当函数运行结束时,其内存块可以再次被用作其它用途。
Dynamic allocation
动态内存分配
Unfortunately, things aren’t quite as easy when we don’t know at compile time how much memory a variable will need. Suppose we want to do something like the following:
不幸的是,想要知道编译时一个变量需要多少内存并没有想象中那般容易。设想一下若要做类似如下事情:
1 | int n = readInput(); // 从用户读取信息 |
Here, at compile time, the compiler does not know how much memory the array will need because it is determined by the value provided by the user.
这里,编译器并不知道编译时数组需要多少内存,因为这是由用户输入的数组元素的值所决定的。
It, therefore, cannot allocate room for a variable on the stack. Instead, our program needs to explicitly ask the operating system for the right amount of space at run-time. This memory is assigned from the heap space. The difference between static and dynamic memory allocation is summarized in the following table:
因此,就不能够在堆栈中为变量分配内存空间。相反,程序需要在运行时显式地从操作系统分配到正确的内存空间。这里的内存是由动态内存空间所分配的。静态和动态内存分配的差异总结如下图表:

To fully understand how dynamic memory allocation works, we need to spend more time on pointers, which might be a bit too much of a deviation from the topic of this post. If you’re interested in learning more, just let me know in the comments and we can go into more details about pointers in a future post.
为了完全理解动态内存分配的工作原理,我们需要花点时间了解指针,这个就可能有点跑题了。如果你对指针感兴趣,请留言,然后我们将会在以后的章节中讨论更多关于指针的内容。
Allocation in JavaScript
JavaScript中的内存分配
Now we’ll explain how the first step (allocate memory) works in JavaScript.
现在,我们将会介绍在 JavaScript 中是如何分配内存的((第一步)。
JavaScript relieves developers from the responsibility to handle memory allocations — JavaScript does it by itself, alongside declaring values.
JavaScript 通过声明变量值,自己处理内存分配工作而不需要开发者干涉。
1 | var n = 374; // 为数字分配内存 |
Some function calls result in object allocation as well:
一些函数调用也会分配一个对象:
1 | var d = new Date(); // 为日期对象分配内存 |
Methods can allocate new values or objects:
可以分配值或对象的方法:
1 | var s1 = 'sessionstack'; |
Using memory in JavaScript
JavaScript中的使用内存
Using the allocated memory in JavaScript basically, means reading and writing in it.
JavaScript 中使用分配的内存主要指的是内存读写。
This can be done by reading or writing the value of a variable or an object property or even passing an argument to a function.
可以通过为变量或者对象属性赋值,亦或是为函数传参来使用内存。
Release when the memory is not needed anymore
释放不再使用的内存
Most of the memory management issues come at this stage.
大多数的内存管理问题出现在这一阶段。
The hardest task here is to figure out when the allocated memory is not needed any longer. It often requires the developer to determine where in the program such piece of memory is not needed anymore and free it.
难点在于检测出何时分配的内存是闲置的。它经常会要求开发者来决定程序中的这段内存是否已经不再使用,然后释放它。
High-level languages embed a piece of software called garbage collector which job is to track memory allocation and use in order to find when a piece of allocated memory is not needed any longer in which case, it will automatically free it.
高级程序语言集成了一块称为垃圾回收器的软件,该软件的工作就是追踪内存分配和使用情况以便找出并自动释放闲置的分配内存片段。
Unfortunately, this process is an approximation since the general problem of knowing whether some piece of memory is needed is undecidable (can’t be solved by an algorithm).
不幸的是,这是个近似的过程,因为判定一些内存片段是否闲置的普遍问题在于其不可判定性(不能为算法所解决)。
Most garbage collectors work by collecting memory which can no longer be accessed, e.g. all variables pointing to it went out of scope. That’s, however, an under-approximation of the set of memory spaces that can be collected, because at any point a memory location may still have a variable pointing to it in scope, yet it will never be accessed again.
大多数的垃圾回收器会收集那些不再被访问的内存,比如引用该内存的所有变量超出了内存寻址范围。然而还是会有低于近似值的内存空间被收集,因为在任何情况下仍然可能会有变量在内存寻址范围内引用该内存地址,即使该内存是闲置的。
Garbage collection
垃圾回收
Due to the fact that finding whether some memory is “not needed anymore” is undecidable, garbage collections implement a restriction of a solution to the general problem. This section will explain the necessary notions to understand the main garbage collection algorithms and their limitations.
由于找出 “不再使用” 的内存的不可判定性,针对这一普遍问题,垃圾回收实现了一个有限的解决方案。本小节将会阐述必要的观点来理解主要的内存垃圾回收算法及其局限性。
Memory references
内存引用
The main concept garbage collection algorithms rely on is the one of reference.
引用是内存垃圾回收算法所依赖的主要概念之一。
Within the context of memory management, an object is said to reference another object if the former has an access to the latter (can be implicit or explicit). For instance, a JavaScript object has a reference to its prototype (implicit reference) and to its properties’ values (explicit reference).
在内存管理上下文中,如果对象 A 访问了另一个对象 B 表示 A 引用了对象 B(可以隐式或显式)。举个栗子,一个 JavaScript 对象有引用了它的原型(隐式引用)和它的属性值(显式引用)。
In this context, the idea of an “object” is extended to something broader than regular JavaScript objects and also contains function scopes (or the global lexical scope).
在这个上下文中,”对象” 的概念被拓展超过了一般的 JavaScript 对象, 并且还包含函数作用域(或者全局词法作用域)。
Lexical Scoping defines how variable names are resolved in nested functions: inner functions contain the scope of parent functions even if the parent function has returned.
词法作用域定义了如何在嵌套函数中解析变量名。即使父函数已经返回,内部的函数仍然会包含父函数的作用域。
Reference-counting garbage collection
垃圾回收引用计数
This is the simplest garbage collection algorithm. An object is considered “garbage collectible” if there are zero references pointing to it.
这是最简单的内存垃圾回收算法。当一个对象被引用0次,会被标记为 “可回收内存垃圾”。
Take a look at the following code:
看如下代码:
1 | var o1 = { |
Cycles are creating problems
循环引用是个问题
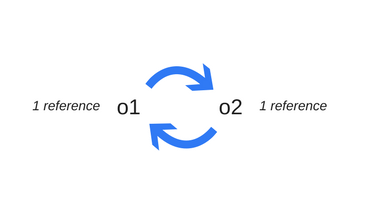
There is a limitation when it comes to cycles. In the following example, two objects are created and reference one another, thus creating a cycle. They will go out of scope after the function call, so they are effectively useless and could be freed. However, the reference-counting algorithm considers that since each of the two objects is referenced at least once, neither can be garbage-collected.
循环引用会造成限制。在以下的示例中,创建了两个互相引用的对象,这样就会造成循环引用。函数调用之后他们将会超出范围,所以,实际上它们是无用且可以释放对他们的引用。然而,引用计数算法会认为由于两个对象都至少互相引用一次,所以他们都不可回收的。
1 | function f() { |
Mark-and-sweep algorithm
标记清除法
In order to decide whether an object is needed, this algorithm determines whether the object is reachable.
为了判断是否需要释放对对象的引用,算法会确定该对象是否可获得。
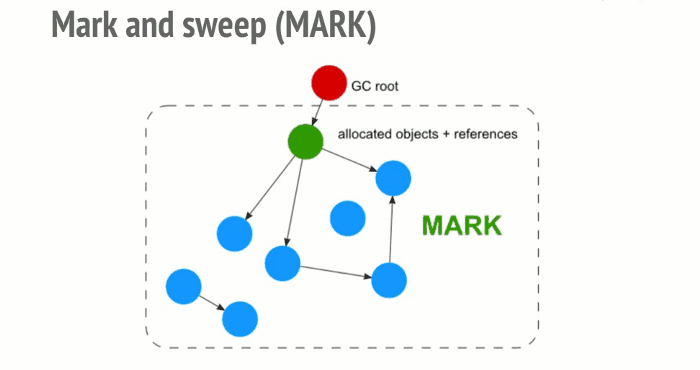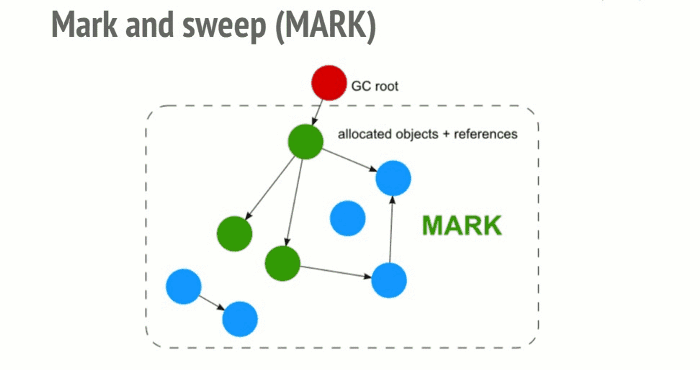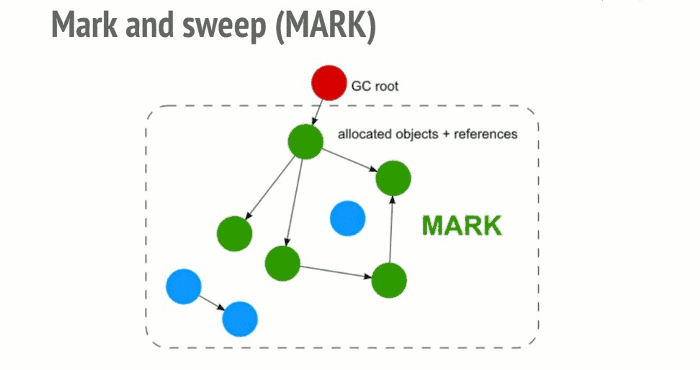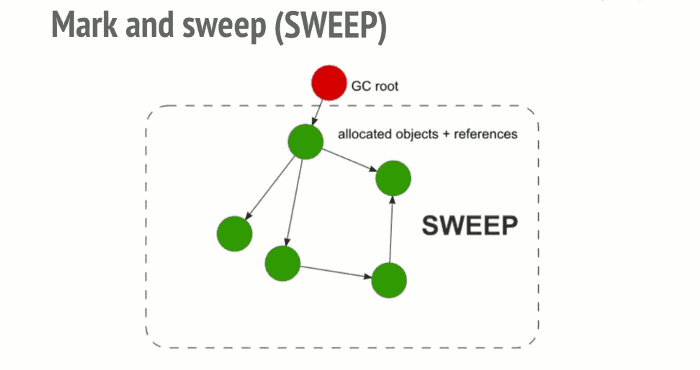
The Mark-and-sweep algorithm goes through these 3 steps:
标记-清除算法包含三个步骤:
- Roots: In general, roots are global variables which get referenced in the code. In JavaScript for example, a global variable that can act as a root is the “window” object. The identical object in Node.js is called “global”. A complete list of all roots gets built by the garbage collector.
- 一般来说,根指的是代码中引用的全局变量。就拿 JavaScript 来说,window 对象即是根的全局变量。Node.js 中相对应的变量为 “global”。垃圾回收器会构建出一份所有根变量的完整列表。
- The algorithm then inspects all roots and their children and marks them as active (meaning, they are not garbage). Anything that a root cannot reach will be marked as garbage.
- 随后,算法会检测所有的根变量及他们的后代变量并标记它们为激活状态(表示它们不可回收)。任何根变量所到达不了的变量(或者对象等等)都会被标记为内存垃圾。
- Finally, the garbage collector frees all memory pieces that are not marked as active and returns that memory to the OS.
- 最后,垃圾回收器会释放所有非激活状态的内存片段然后返还给操作系统。
This algorithm is better than the previous one since “an object has zero reference” leads to this object being unreachable. The opposite is not true as we have seen with cycles.
该算法比之前的算法要好,因为对象零引用可以让对象不可获得。反之则不然,正如之前所看到的循环引用。
As of 2012, all modern browsers ship a mark-and-sweep garbage-collector. All improvements made in the field of JavaScript garbage collection (generational/incremental/concurrent/parallel garbage collection) over the last years are implementation improvements of this algorithm (mark-and-sweep), but not improvements over the garbage collection algorithm itself, nor its goal of deciding whether an object is reachable or not.
从 2012 年起,所有的现代浏览器都内置了一个标记-清除垃圾回收器。前些年所有对于 JavaScript 内存垃圾收集(分代/增量/并发/并行 垃圾收集)的优化都是针对标记-清除算法的实现的优化,但既没有提升垃圾收集算法本身,也没有提升判定对象是否可获得的能力。
In this article, you can read in a greater detail about tracing garbage collection that also covers mark-and-sweep along with its optimizations.
你可以查看这篇文章 来了解追踪内存垃圾回收的详情及包含优化了的标记-清除算法。
Cycles are not a problem anymore
循环引用不在是问题
In the first example above, after the function call returns, the two objects are not referenced anymore by something reachable from the global object. Consequently, they will be found unreachable by the garbage collector.
在之前的第一个示例中,当函数返回,全局对象不再引用这两个对象。结果,内存垃圾回收器发现它们是不可获得的。
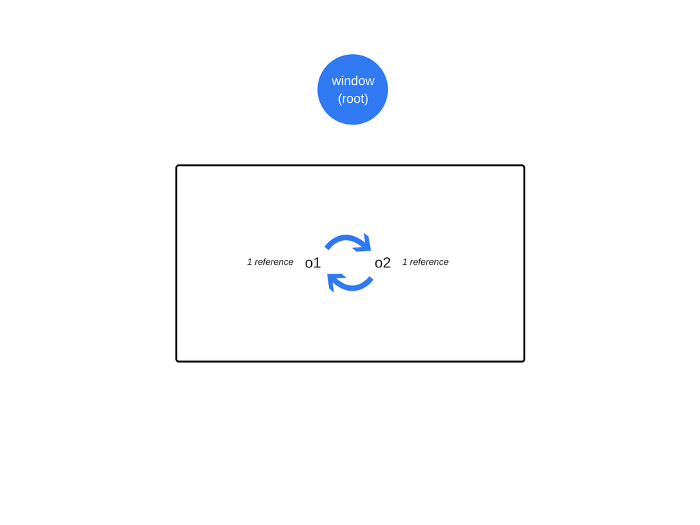
Even though there are references between the objects, they’re not reachable from the root.
即使两个对象互相引用,也不能够从根变量获得他们。
Counter intuitive behavior of Garbage Collectors
内存垃圾回收器的反直觉行为
Although Garbage Collectors are convenient they come with their own set of trade-offs. One of them is non-determinism. In other words, GCs are unpredictable. You can’t really tell when a collection will be performed. This means that in some cases programs use more memory that it’s actually required. In other cases, short-pauses may be noticeable in particularly sensitive applications. Although non-determinism means one cannot be certain when a collection will be performed, most GC implementations share the common pattern of doing collection passes during allocation. If no allocations are performed, most GCs stay idle. Consider the following scenario:
虽然内存垃圾回收器很方便,但是它们也有其一系列的代价。其中之一便是不确定性。也就是说内存垃圾回收具有不可预见性。你不能确定内存垃圾收集的确切时机。这意味着在某些情况下,程序会使用比实际需要更多的内存。在其它情况下,在特定的交互敏感的程序中,你也许需要注意那些内存垃圾收集短暂停时间。虽然不确定性意味着不能够确定什么时候可以进行内存垃圾收集,但是大多数 GC 的实现都是在内存分配期间进行内存垃圾回收的一般模式。如果没有进行内存分配,大多数的内存垃圾回收就会保持闲置状态。考虑以下情况:
- A sizable set of allocations is performed.
- 分配一段固定大小的内存
- Most of these elements (or all of them) are marked as unreachable (suppose we null a reference pointing to a cache we no longer need).
- 大多数的元素(或所有)被标记为不可获得(假设我们赋值我们不再需要的缓存为 null )
- No further allocations are performed.
- 不再分配其它内存。
In this scenario, most GCs will not run any further collection passes. In other words, even though there are unreachable references available for collection, these are not claimed by the collector. These are not strictly leaks but still, result in higher-than-usual memory usage.
在该情况下,大多数的内存垃圾回收器不会再运行任何的内存垃圾回收。换句话说,即使可以对该不可获得的引用进行垃圾回收,但是内存收集器不会进行标记。虽然这不是严格意义上的内存泄漏,但是这会导致高于平常的内存使用率。
What are memory leaks?
什么是内存泄露?
Just like the memory suggests, memory leaks are pieces of memory that the application have used in the past but is not needed any longer but has not yet been return back to the OS or the pool of free memory.
正如内存管理所说的那样,内存泄漏即一些程序在过去时使用但处于闲置状态,却没有返回给操作系统或者可用的内存池。

Programming languages favor different ways of managing memory. However, whether a certain piece of memory is used or not is actually an undecidable problem. In other words, only developers can make it clear whether a piece of memory can be returned to the operating system or not.
编程语言支持多种内存管理方法。然而,某个内存片段是否被使用是一个不确定的问题。换句话说,只有开发人员清楚某个内存片段是否可以返回给操作系统。
Certain programming languages provide features that help developers do this. Others expect developers to be completely explicit about when a piece of memory is unused. Wikipedia has good articles on manual and automatic memory management.
某些编程语言会为开发者提供功能函数来解决这个问题。其它的编程语言完全依赖于开发者全权掌控哪个内存片段是可回收的。维基百科上有关于手动和自动内存管理的好文章。
The four types of common JavaScript leaks
四种常见的 JavaScript 内存泄漏
- Global variables
- 全局变量
JavaScript handles undeclared variables in an interesting way: when a undeclared variable is referenced, a new variable gets created in the global object. In a browser, the global object would be window, which means that
JavaScript 以一种有趣的方式来处理未声明变量:当引用一个未声明的变量,会在全局对象上创建一个新的变量。在浏览器中,全局对象是
window,这意味着如下代码:
1 | function foo(arg) { |
is the equivalent of:
等同于:
1 | function foo(arg) { |
Let’s say the purpose of bar is to only reference a variable in the foo function. A redundant global variable will be created, however, if you don’t use var to declare it. In the above case, this won’t cause much harm. You can surely imagine a more damaging scenario though.
变量
bar本意是只能在foo函数中被引用。但是如果你没有用var来声明变量,那么将会创建一个多余的全局变量。在上面的例子中,并不会造成大的事故。但你可以很自然地想象一个更具破坏性的场景。
You can also accidentally create a global variable using this:
你也可以使用
this关键字不经意地创建一个全局变量。
1 | function foo() { |
You can avoid all this by adding
‘use strict’;at the beginning of your JavaScript file which would switch on a much stricter mode of parsing JavaScript which prevents the unexpected creation of global variables.
你可以通过在 JavaScript 文件的顶部添加'use strict'来避免以上的所有问题,'use strict'会切换到更加严格的 JavaScript 解析模式,这样就可以防止创建意外的全局变量。
Unexpected globals is certainly an issue, however, more often than not your code would be infested with explicit global variables which by definition cannot be collected by the garbage collector. Special attention needs to be given to global variables used to temporarily store and process large bits of information. Use global variables to store data if you must but when you do, make sure to assign it as null or reassign it once you are done with it.
意外的全局变量的确是个问题,而代码经常会被显式定义的全局变量所污染,根据定义这些全局变量是不会被内存垃圾回收器所收集的。你需要特别注意的是使用全局变量来临时存储和处理大型的位信息。只有在必要的时候使用全局变量来存储数据,记得一旦你不再使用的时候,把它赋值为 null 或者对其再分配。
- Timers or callbacks that are forgotten
- 定时器及被遗忘的回调函数
Let’s take setInterval for example as it’s often used in JavaScript.
因为经常在 JavaScript 中使用
setInterval,所以让我们以它为例。
Libraries which provide observers and other instruments that accept callbacks usually make sure all references to the callbacks become unreachable once their instances are unreachable too. Still, the code below is not a rare find:
框架中提供了观察者和接受回调的其它指令通常会确保当他们的实例不可获得的时候,所有对回调的引用都会变成不可获得。很容易找到如下代码:
1 | var serverData = loadData(); |
The snippet above shows the consequences of using timers that reference nodes or data that’s no longer needed.
以上代码片段展示了使用定时器来引用不再需要的节点或数据的后果。
The renderer object may be replaced or removed at some point which would make the block encapsulated by the interval handler redundant. If this happens, neither the handler, nor its dependencies would be collected as the interval would need to be stopped first (remember, it’s still active). It all boils down to the fact that serverData which surely stores and processes loads of data will not be collected either.
renderer对象会在某些时候被替换或移除,这样就会导致由定时处理程序封装的代码变得冗余。当这种情况发生的时候,不管是定时处理程序还是它的依赖都不会被垃圾回收,这是由于需要先停止定时器(记住,定时器仍然处于激活状态)。这可以归结为保存和处理数据加载的serverData变量也不会被垃圾回收。
When using observers, you need to make sure you make an explicit call to remove them once you are done with them (either the observer is not needed anymore, or the object will become unreachable).
当使用观察者的时候,你需要确保一旦你不再需要它们的时候显式地移除它们(不再需要观察者或者对象变得不可获得)。
Luckily, most modern browsers would do the job for you: they’ll automatically collect the observer handlers once the observed object becomes unreachable even if you forgot to remove the listener. In the past some browsers were unable to handle these cases (good old IE6).
幸运的是,大多数现代浏览器都会替你进行处理:当被观察者对象变得不可获得时,即使你忘记移除事件监听函数,浏览器也会自动回收观察者处理程序。以前,一些老掉牙的浏览器处理不了这些情况(如老旧的 IE6)。
Still, though, it’s in line with best practices to remove the observers once the object becomes obsolete. See the following example:
那么,最佳实践是当对象被废弃的时候,移除观察者处理程序。查看如下例子:
1 | var element = document.getElementById('launch-button'); |
You no longer need to call removeEventListener before making a node unreachable as modern browsers support garbage collectors that can detect these cycles and handle them appropriately.
在让一个 DOM 节点不可获得之前,你不再需要调用 removeEventListener,因为现代浏览器支持用内存垃圾回收器来检测并适当地处理 DOM 节点的生命周期。
If you leverage the jQuery APIs (other libraries and frameworks support this too) you can also have the listeners removed before a node is made obsolete. The library would also make sure there are no memory leaks even when the application is running under older browser versions.
如果你使用 jQuery API(其它的库和框架也支持的 API),你可以在废弃节点之前移除事件监听函数。jQuery 也会确保即使在老旧的浏览器之中,也不会产生内存泄漏。
- Closures
- 闭包
A key aspect of JavaScript development are closures: an inner function that has access to the outer (enclosing) function’s variables. Due to the implementation details of the JavaScript runtime, it is possible to leak memory in the following way:
闭包是 JavaScript 的一个重要功能:嵌套函数可以访问外部(封闭)函数的变量。鉴于 JavaScript 运行时的实现细节,以下方法可能会造成内存泄漏:
1 | var theThing = null; |
Once replaceThing is called, theThing gets a new object which consists of a big array and a new closure (someMethod). Yet, originalThing is referenced by a closure that’s held by the unused variable (which is theThing variable from the previous call to replaceThing). The thing to remember is that once a scope for closures is created for closures in the same parent scope, the scope is shared.
当调用
replaceThing的时候,theThing对象由一个大数组和新的闭包(someMethod)所组成。而originalThing由unused变量创建的闭包所引用(即引用replaceThing函数之前的theThing变量)。需要记住的是当为同一个父作用域中的闭包创建闭包作用域的时候,该闭包作用域是共享的。
In this case, the scope created for the closure someMethod is shared with unused. unused has a reference to originalThing. Even though unused is never used, someMethod can be used through theThing outside of the scope of replaceThing (e.g. somewhere globally). And as someMethod shares the closure scope with unused, the reference unused has to originalThing forces it to stay active (the whole shared scope between the two closures). This prevents its collection.
在这样的情况下,闭包
someMethod和unused共享相同的作用域。unused引用了origintalThing。即使unused永不使用,也可以通过theThing在replaceThing的作用域外使用someMethod函数(例如,全局某处)。然后由于someMethod和unused共享相同的闭包作用域,unused变量引用originalThing会强迫unused保持激活状态(两个闭包共享作用域)。这会阻止内存垃圾回收。
In the above example, the scope created for the closure someMethod is shared with unused, while unused references originalThing. someMethod can be used through theThing outside of the replaceThing scope, despite the fact that unused is never used. The fact that unused references originalThing requires that it remains active since someMethod shares the closure scope with unused.
在以上例子中,闭包
someMethod和unused共享作用域,而unused引用origintalThing。可以在replaceThing作用域外通过theThing使用someMethod,即使unused从未被使用。事实上,由于someMethod和unused共享闭包作用域,unused引用origintalThing要求unused保持激活状态。
All this can result in a considerable memory leak. You can expect to see a spike in memory usage when the above snippet is run over and over again. Its size won’t shrink when the garbage collector runs. A linked list of closures is created (its root is theThing variable in this case), and each the closure scopes carries forward an indirect reference to the big array.
所有的这些行为会导致内存泄漏。当你不断地运行如上代码片段,你将会发现飙升的内存使用率。当内存垃圾回收器运行的时候,这些内存使用率不会下降。这里会创建出一份闭包链表(当前情况下,其根变量是
theThing),每个闭包作用域都间接引用了大数组。
This issue was found by the Meteor team and they have a great article that describes the issue in great detail.
该问题是由 Metor 小组发现的并且他们写了一篇很好的文章来详细描述该问题。
- Out of DOM references
- 出于DOM引用
There are cases in which developers store DOM nodes inside data structures. Suppose you want to rapidly update the contents of several rows in a table. If you store a reference to each DOM row in a dictionary or an array, there will be two references to the same DOM element: one in the DOM tree and another in the dictionary. If you decide to get rid of these rows, you need to remember to make both references unreachable.
有时候,开发者会在数据结构中存储 DOM 节点。假设你想要快速更新几行表格内容。如果你在一个字典或者数组中保存对每个表格行的引用,这将会造成重复引用相同的 DOM 元素:一个在 DOM 树中而另一个在字典中。如果你想要释放对这些表格行的引用,你需要记得让这些引用变成不可获得。
1 | var elements = { |
There’s an additional consideration that has to be taken into account when it comes to references to inner or leaf nodes inside a DOM tree. If you keep a reference to a table cell (a <td> tag) in your code and decide to remove the table from the DOM yet keep the reference to that particular cell, you can expect a major memory leak to follow. You might think that the garbage collector would free up everything but that cell. This will not be the case, however. Since the cell is a child node of the table and children keep references to their parents, this single reference to the table cell would keep the whole table in memory.
你还需要额外考虑的情况是引用 DOM 树中的内节点或者叶节点。如果你在代码中保存着对一个单元格的引用,这时候当你决定从 DOM 中移除表格,却仍然会保持对该单元格的引用,这就会导致大量的内存泄漏。你可以认为内存垃圾回收器将会释放除了该单元格以外的内存。而这还没完。因为单元格是表格的一个后代元素而后代元素保存着对其父节点的引用,对一个单元格的引用会导致无法释放整个表格所占用的内存。
以下非原文:
内存管理心得
以下内容为个人原创分享。By 三月。
指导思想
尽可能减少内存占用,尽可能减少 GC。
减少 GC 次数
浏览器会不定时回收垃圾内存,称为 GC,不定时触发,一般在向浏览器申请新内存时,浏览器会检测是否到达一个临界值再进行触发。一般来说,GC 会较为耗时,GC 触发时可能会导致页面卡顿及丢帧。故我们要尽可能避免GC的触发。GC 无法通过代码触发,但部分浏览器如 Chrome,可在 DevTools -> TimeLine 页面手动点击 CollectGarbage 按钮触发 GC。
减少内存占用
降低内存占用,可避免内存占用过多导致的应用/系统卡顿,App 闪退等,在移动端尤为明显。当内存消耗较多时,浏览器可能会频繁触发 GC。而如前所述,GC 发生在申请新内存时,若能避免申请新内存,则可避免GC 触发。
优化方案
使用对象池
对象池 (英语:object pool pattern)是一种设计模式。 一个对象池包含一组已经初始化过且可以使用的对象,而可以在有需求时创建和销毁对象。池的用户可以从池子中取得对象,对其进行操作处理,并在不需要时归还给池子而非直接销毁它。这是一种特殊的工厂对象。
若初始化、实例化的代价高,且有需求需要经常实例化,但每次实例化的数量较少的情况下,使用对象池可以获得显著的效能提升。从池子中取得对象的时间是可预测的,但新建一个实例所需的时间是不确定。
以上摘自维基百科。
使用对象池技术能显著优化需频繁创建对象时的内存消耗,但建议按不同使用场景做以下细微优化。
按需创建
默认创建空对象池,按需创建对象,用完归还池子。
预创建对象
如在高频操作下,如滚动事件、TouchMove事件、resize事件、for 循环内部等频繁创建对象,则可能会触发GC的发生。故在特殊情况下,可优化为提前创建对象放入池子。
高频情况下,建议使用截流/防抖及任务队列相关技术。
定时释放
对象池内的对象不会被垃圾回收,若极端情况下创建了大量对象回收进池子却不释放只会适得其反。
故池子需设计定时/定量释放对象机制,如以已用容量/最大容量/池子使用时间等参数来定时释放对象。
其他优化tips
尽可能避免创建对象,非必要情况下避免调用会创建对象的方法,如
Array.slice、Array.map、Array.filter、字符串相加、$('div')、ArrayBuffer.slice等。不再使用的对象,手动赋为 null,可避免循环引用等问题。
使用 Weakmap
生产环境勿用
console.log大对象,包括 DOM、大数组、ImageData、ArrayBuffer 等。因为console.log的对象不会被垃圾回收。详见Will console.log prevent garbage collection?。合理设计页面,按需创建对象/渲染页面/加载图片等。
避免如下问题:
- 为了省事儿,一次性请求全部数据。
- 为了省事儿,一次性渲染全部数据,再做隐藏。
- 为了省事儿,一次性加载/渲染全部图片。
使用重复 DOM 等,如重复使用同一个弹窗而非创建多个。
如 Vue-Element 框架中,PopOver/Tooltip 等组件用于表格内时会创建 m * n 个实例,可优化为只创建一个实例,动态设置位置及数据。
ImageData 对象是 JS 内存杀手,避免重复创建 ImageData 对象。
重复使用 ArrayBuffer。
压缩图片、按需加载图片、按需渲染图片,使用恰当的图片尺寸、图片格式,如 WebP 格式。
图片处理优化
假设渲染一张 100KB 大小,300x500 的透明图片,粗略的可分为三个过程:
加载图片
加载图片二进制格式到内存中并缓存,此时消耗了100KB 内存 & 100KB 缓存。
解码图片
将二进制格式解码为像素格式,此时占用宽 高 24(透明为32位)比特大小的内存,即 300 500 32,约等于 585 KB,这里约定名为像素格式内存。个人猜测此时浏览器会回收加载图片时创建的 100KB 内存。
渲染图片
通过 CPU 或 GPU 渲染图片,若为 GPU 渲染,则还需上传到 GPU 显存,该过程较为耗时,由图片尺寸 / 显存位宽决定,图片尺寸越大,上传时间越慢,占用显存越多。
其中,较旧的浏览器如Firefox回收像素内存时机较晚,若渲染了大量图片时会内存占用过高。
PS:浏览器会复用同一份图片二进制内存及像素格式内存,浏览器渲染图片会按以下顺序去获取数据:
显存 >> 像素格式内存 >> 二进制内存 >> 缓存 >> 从服务器获取。我们需控制和优化的是二进制内存及像素内存的大小及回收。
总结一下,浏览器渲染图片时所消耗内存由图片文件大小内存、宽高、透明度等所决定,故建议:
使用 CSS3、SVG、IconFont、Canvas 替代图片。展示大量图片的页面,建议使用 Canvas 渲染而非直接使用img标签。具体详见 Javascript的Image对象、图像渲染与浏览器内存两三事。
适当压缩图片,可减小带宽消耗及图片内存占用。
使用恰当的图片尺寸,即响应式图片,为不同终端输出不同尺寸图片,勿使用原图缩小代替 ICON 等,比如一些图片服务如 OSS。
使用恰当的图片格式,如使用WebP格式等。详细图片格式对比,使用场景等建议查看web前端图片极限优化策略。
按需加载及按需渲染图片。
预加载图片时,切记要将 img 对象赋为 null,否则会导致图片内存无法释放。
当实际渲染图片时,浏览器会从缓存中再次读取。
将离屏 img 对象赋为 null,src 赋为 null,督促浏览器及时回收内存及像素格式内存。
将非可视区域图片移除,需要时再次渲染。和按需渲染结合时实现很简单,切换 src 与 v-src 即可。





.jpg)