博客优化二三事 前言 交代一下背景,这个博客是最开始是基于jekyll搭建的github page,但是由于一些原因(主要是jekyll的主题觉得不好看), 寻寻觅觅,终于找到一个喜欢的主题,是基于Vuepress的,主题用的是vuepress-theme-modern-blog ,于是就把博客迁移到基于Vuepress的github page。具体的迁移过程不复杂,个人的.vuepress/config.js可参考这里 ,在这篇文章就不再赘述。这篇文章主要打算记录一下迁移到Vuepress之后的一些问题的解决方法。
评论系统 迁移文章其实比较简单,因为都是一些markdown文件,也没什么需要改的。但是原来的评论系统不能用啦,vuepress-theme-modern-blog给出了一个评论系统disqus,但是这个评论系统在国内由于防火墙的原因支持的不太好。于是发现了Vssue评论系统,经过咔咔一顿配置(主要是github的access token等),在一个md文件的最后添加<Vssue :title="$title" />一测试可以用,开心啊。但是接着问题就来啦,文章说多不多,说少不少,也不能一个个的手动去添加吧,好麻烦。于是写了个脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const fs = require ('fs' );const reg = /^.*\.md$/ ;const _path = './_posts' let all_files = fs.readdirSync (_path);let files = all_files.filter (item =>test (item));files.forEach (item => try { fs.appendFileSync (`${_path} /${item} ` , '\n\n<Vssue :title="$title" />\n' ); } catch (err) { console .log (err); } })
齐活~~
但是好景不长,这个Vssue插件的用的代理cors-anywhere应该是做了一些限制,导致获取授权access_token的接口返回403,导致登录github失败,无发评论。在网上看了一些解决办法,但都以失败告终。于是选择了更换评论系统,经过比较我选择了gittalk,因为相对而言,更换到gittalk的成本比较低。具体的文章可参考为你的VuePress博客添加GitTalk评论 。
这个时候需要一个删除之前添加的<Vssue :title="$title" />的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 const fs = require ('fs' );const reg = /^.*\.md$/ ;const _path = './_posts' let all_files = fs.readdirSync (_path);let files = all_files.filter (item =>test (item));files.forEach (item => try { fs.readFile (`${_path} /${item} ` , 'utf-8' , (err, data ) => { if (err) console .log (err); fs.writeFile (`${_path} /${item} ` , data.replace (/\n\n<Vssue.*\/>/g , '' ), (err ) => { if (err) console .log (err) }) }) } catch (err) { console .log (err); } })
添加(或者删除)gittalk的评论组件的脚本依然可以用append.js(或者deleteComponent.js),只不过需要改一下脚本中需要添加和删除的内容。
这样就ok啦。
修改主题,单独发包 在使用这个vuepress-theme-modern-blog主题的时候发现了一些问题,当然也不全是问题,如果全是问题我就给作者提PR了,还有的是一些自己的需求。
比如:图标,由于在国内像instagram、Twitter、linkedin等国外网站都不太好访问,也没有账号,所以第一步就是换图标,主要是在iconfont ,找图标然后替换,在这个过程中修改了一些代码。还有文章的末尾的轮播文章卡片,我不喜欢下面的轮播指示,也做了修改。还有一些其他的修改,比如添加推荐网站卡片、增加了其他tab等。
最开始这些都是直接在本地文件的node_modules中找到这个vuepress-theme-modern-blog包,直接去源文件中进行修改。一开始修改的地方不太多,所以感觉还好。但是随着修改的地方的增加,我开始思考一个问题,如果修改的文件丢失了怎么办,在重新安装这个包,修改的地方就全消失啦。并且随着文章越来越多,每次都要重新打包,全量推送到远程仓库,比较消耗人力。此时就很需要travis CI来帮助我们自动安装依赖,自动打包,然后推送到远程的github page仓库。
出于这两个原因,把这个修改后的主题包发布到npm平台似乎成了一个必要的选择。
发包也比叫简单:
首先要有npm账号,没有可以注册一个。
本地调试:
在要发布的npm包(vuepress-theme-custom)中执行:
在需要用到这个npm包的项目中:
1 npm link vuepress-theme-custom
这样就可以实现本地的npm包进行调试啦。
其实npm link相当于在全局环境下安装了vuepress-theme-custom,在项目中进行npm link vuepress-theme-custom相当于在项目的node_modules中创建了一个这个npm包的符号连接。
添加.travis.yml文件 正如上面提到的那样,每次发布文章都要在本地重新打包,然后把打包后的产物推送到远程分支,比较耗费人力和时间。为了解决这个问题,比较好的解决办法就是引入持续集成和持续发布。
在查阅官方文档后,发现github page的发布有一个模板 (我也不知道叫模板正不正确),如下:
1 2 3 4 5 6 7 deploy: provider: pages skip_cleanup: true github_token: $GITHUB_TOKEN keep_history: true on: branch: main
一些其他的github page配置可参考官方说明 。
我现在用的配置文件为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 language: node_js node_js: - lts/* install: - yarn install script: - node append.js && yarn build && node deleteComponent.js deploy: provider: pages skip_cleanup: true local_dir: .vuepress/dist repo: yancqS/blog github_token: $GH_TOKEN keep_history: true on: branch: master
这里面会涉及到tarvis的job生命周期,具体的要参考官方文档 。
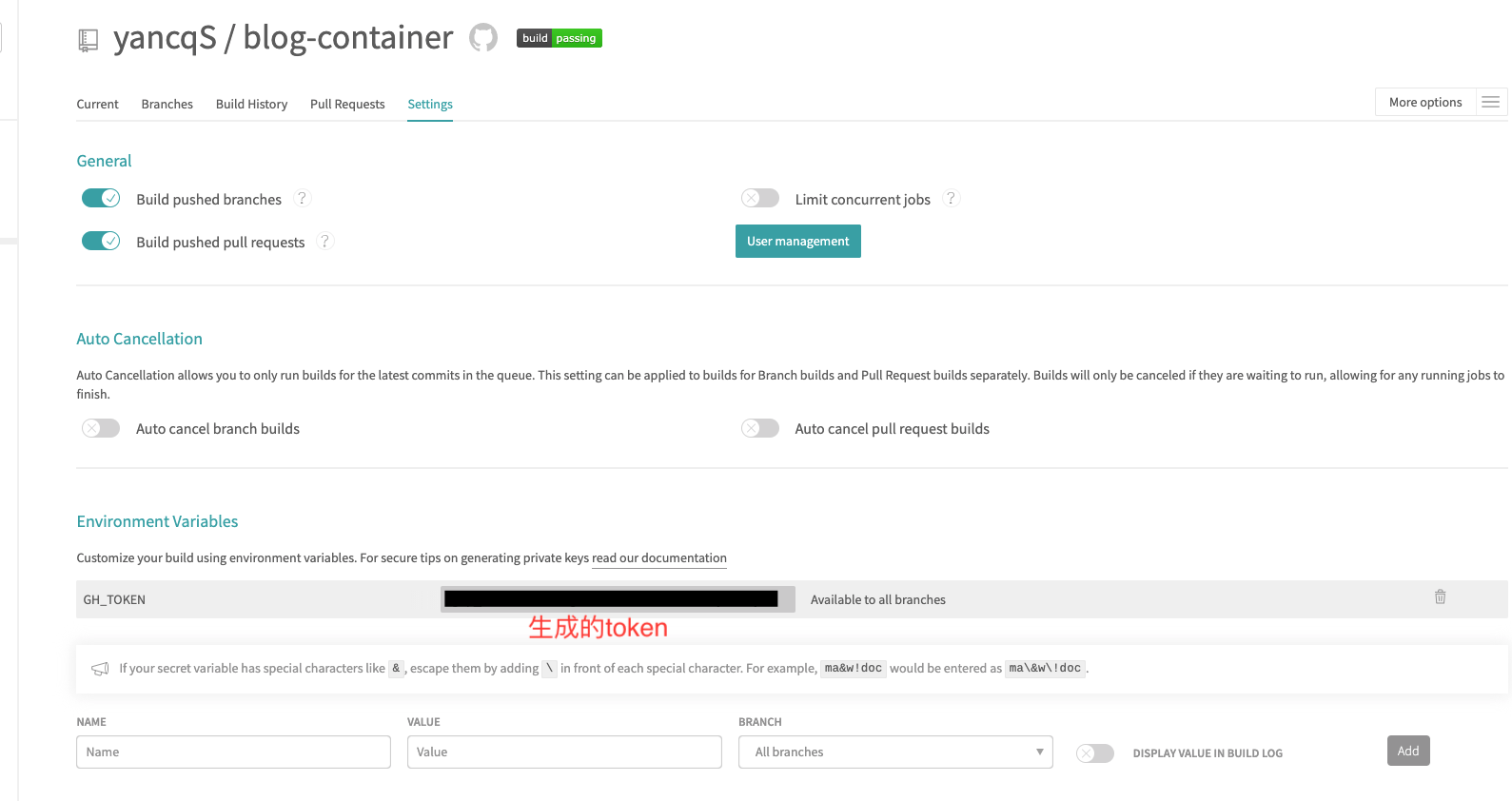
注意:$GH_TOKEN这个是在github生产的token,以允许travis向github平台推送代码。具体的生成方法参考github官网-Creating a personal access token
。由于这个token是保密的,因此这个token值是要在travis的设置中添加为变量的。如下:
还有要记得确认travis的邮箱,否则不会正常触发job。
里面还有一些细节操作,比如选择仓库啥的。
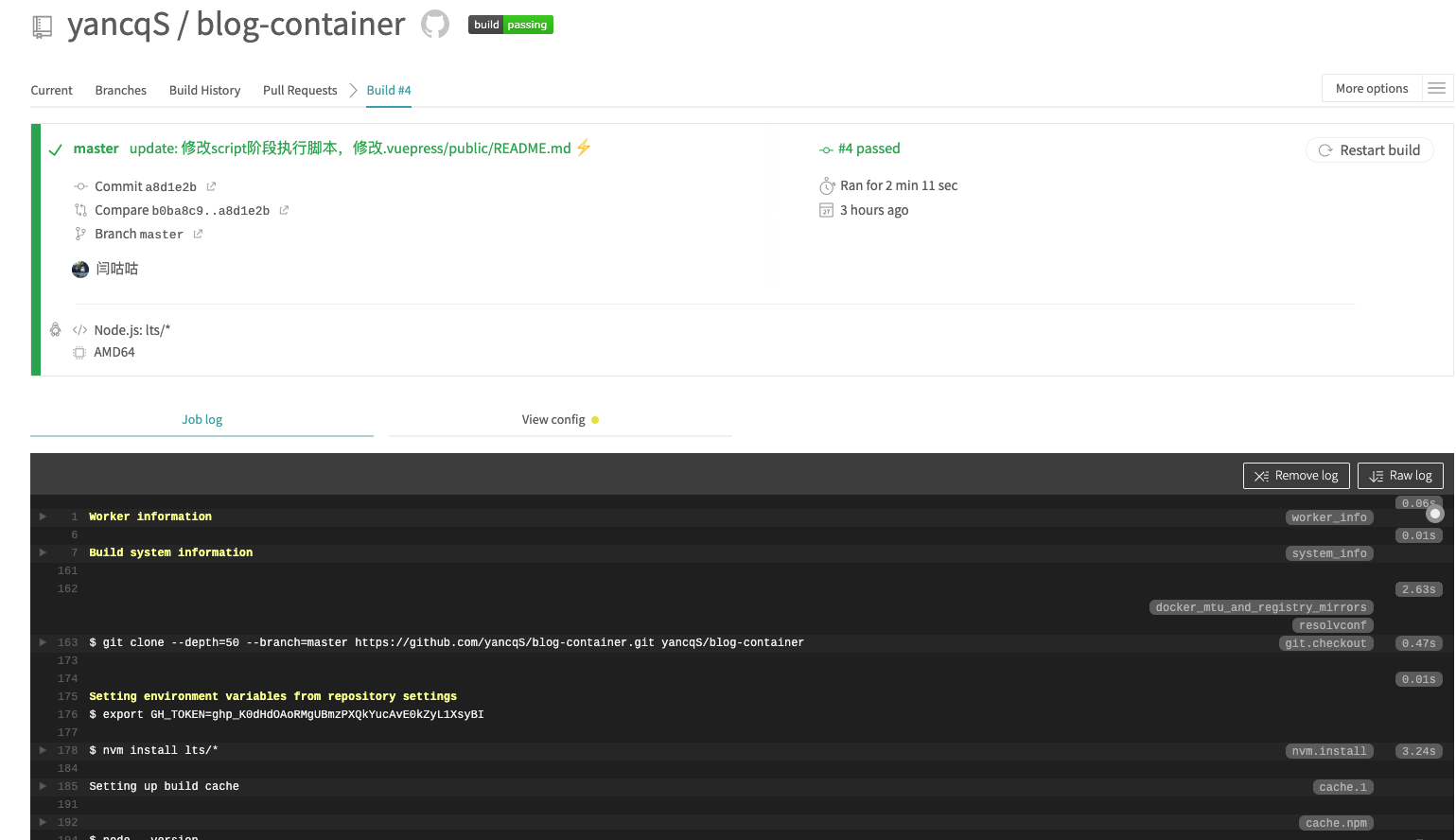
正常情况下到这一步,已经成功啦。现在只要这个仓库有push或者其他动作就会触发这个travis.yml中的任务并执行脚本。
具体如下图:
暂时就先这么多吧,如果以后有啥新的更改,会及时同步。
土遁~~~~~
添加自动生成文章列表README.md的脚本
更新2021-04-23
所谓文章列表README.md就是这个东西:
值得注意的是.vuepress/public/README.md文件会被打包到dist文件夹并被travis推送到仓库。
因此,思路就是在打包前要遍历_post文件夹下面的所有md文件,并对文件名进行处理、以及提取文件标题。并将处理后的内容组合后写入到.vuepress/public/README.md。这个过程完全是在在travis的虚拟机上执行完成的,因此本地不会产生这个README.md文件。
步骤如下:
遍历_post文件夹下面的所有md文件前面已经有相关代码:
1 2 3 4 5 6 7 const fs = require ('fs' );const reg = /^.*\.md$/ ;const _path = './_posts' let all_files = fs.readdirSync (_path);let files = all_files.filter (item =>test (item)).reverse ();
获取文件名(不包含后缀名)
1 2 3 4 5 6 7 8 9 10 11 const fs = require('fs'); + const path = require('path'); const reg = /^.*\.md$/; const _path = './_posts' const base = 'https://yancqs.github.io/blog'; const readme_path = '.vuepress/public/README.md'; let all_files = fs.readdirSync(_path); let files = all_files.filter(item => reg.test(item)).reverse(); + let file_name = files.map(item => path.parse(item).name);
如何把文件名处理为URL
这个可谓是这个脚本的核心说在,首先经过观察和测试可以看出转换规则如下:
以文件名2020-06-02-leetcode-pow(x,n)-50.md为例
线上实际的URL为:${base}/2020/06/02/leetcode-pow-x-n-50/
文件名中的日期2020-06-02会被处理为2020/06/02
文件名中的大写字母要转换为小写字母
文件名中所有非字母、数字都要转换为中划线-
经过这个规则处理之后,我们得到的文件名为2020/06/02/leetcode-pow-x-n--50/,这样显然是不对的,因为连续重复出现的-要处理为1个。这样得出最后一条规则:
经过处理后的URL中连续重复出现的-要替换为1个-
因此得到如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 const fs = require('fs'); const path = require('path'); const reg = /^.*\.md$/; + const reg_paper_name = /([-])\1{1,}/g; const _path = './_posts'; const base = 'https://yancqs.github.io/blog'; let all_files = fs.readdirSync(_path); let files = all_files.filter(item => reg.test(item)).reverse(); let file_name = files.map(item => path.parse(item).name); +let URL = file_name.map(item => { + let date = item.split('-').slice(0, 3).join('/'); + let _paper_name = item.split('-') + .slice(3) + .map(subitem => (subitem + '').toLowerCase()) + .map(lowerString => lowerString.replace(/[^a-z0-9]/g, '-')) + .join('-'); + let paper_name = _paper_name.replace(reg_paper_name, '-'); + return `${base}/${date}/${paper_name}/`; +})
获取文章标题
主要是文章开头的font-matter的格式固定,才可以这样去读文件:
1 2 3 4 5 let data = fs.readFileSync (`${_path} /${item} ` , 'utf-8' );let _title = data.split ('---' )[1 ].split ('\n' )[1 ].split (':' );_title.shift (); let title = _title.join (':' ).trim ();
处理后写入.vuepress/public/README.md
1 2 3 const readme_path = '.vuepress/public/README.md' ;fs.appendFileSync (readme_path, `- [${title} ](${URL[index]} )\n` , 'utf-8' );
整合代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 const fs = require ('fs' );const path = require ('path' );const reg = /^.*\.md$/ ;const reg_paper_name = /([-])\1{1,}/g ;const _path = './_posts' ;const base = 'https://yancqs.github.io/blog' ;const readme_path = '.vuepress/public/README.md' ;let all_files = fs.readdirSync (_path);let files = all_files.filter (item =>test (item)).reverse ();let file_name = files.map (item =>parse (item).name );let URL = file_name.map (item => let date = item.split ('-' ).slice (0 , 3 ).join ('/' ); let _paper_name = item.split ('-' ) .slice (3 ) .map (subitem =>'' ).toLowerCase ()) .map (lowerString =>replace (/[^a-z0-9]/g , '-' )) .join ('-' ); let paper_name = _paper_name.replace (reg_paper_name, '-' ); return `${base} /${date} /${paper_name} /` ; }) if (fs.existsSync (readme_path)) { fs.unlinkSync (readme_path); } fs.writeFileSync (readme_path, `# <center>目录</center>\n\n\n\n` ) files.forEach ((item, index ) => { let data = fs.readFileSync (`${_path} /${item} ` , 'utf-8' ); let _title = data.split ('---' )[1 ].split ('\n' )[1 ].split (':' ); _title.shift (); let title = _title.join (':' ).trim (); fs.appendFileSync (readme_path, `- [${title} ](${URL[index]} )\n` , 'utf-8' ); })
就先到这吧。
最后,记得更新travis.yml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 language: node_js node_js: - lts/* install: - yarn install script: - node getReadme.js && node append.js && yarn build && node deleteComponent.js deploy: provider: pages skip_cleanup: true local_dir: .vuepress/dist repo: yancqS/blog github_token: $GH_TOKEN keep_history: true on: branch: master