
Web Speech API
Web Speech API
前言
前几天在看阮一峰老师的科技爱好者周刊173期时看到一篇关于语音识别的文章——Voice to Text with Chrome Web Speech API。网页、语音识别、语音合成感觉挺好玩的,了解了一下。
正文
Web Speech API 有两个部分:SpeechSynthesis 语音合成 (文本到语音 TTS) 和 SpeechRecognition 语音识别 (异步语音识别)。
语音识别通过 SpeechRecognition 接口进行访问,它提供了识别从音频输入(通常是设备默认的语音识别服务)中识别语音情景的能力。一般来说,你将使用该接口的构造函数来构造一个新的 SpeechRecognition 对象,该对象包含了一系列有效的对象处理函数来检测识别设备麦克风中的语音输入。
SpeechRecognition
兼容性

语音识别对象SpeechRecognition有许多属性、方法和事件处理程序。有关完整接口列表,请参阅https://w3c.github.io/speech-api/#speechreco-section
1 | interface SpeechRecognition : EventTarget { |
Properties
需要重点介绍的两个属性:SpeechRecognition.continuous 和 SpeechRecognition.interimResults.
当SpeechRecognition.continuous设置为true时,识别引擎将把你讲话的每一部分都视为临时结果。当SpeechRecognition.interimResults设置为true时,临时结果将会被返回。
maxAlternatives此属性将设置每个结果的 SpeechRecognitionAlternatives 的最大数量。 默认值为 1。
1 | interface SpeechRecognitionAlternative { |
其他属性的含义可参考MDN-Web Speech API
Methods
SpeechRecognition.abort()
语音识别服务停止接受传入的音频,并且不返回SpeechRecognitionResult。
SpeechRecognition.start()
启动语音识别服务,接受传入的音频,以识别与当前SpeechRecognition关联的
grammars。SpeechRecognition.stop()
语音识别服务停止接受传入的音频,返回SpeechRecognitionResult。
1 | interface SpeechRecognitionResultList { |
Event
最值得强调的事件是result.
此事件当语音识别服务返回结果时触发-一个单词或短语已被正确识别,并已反馈给应用程序。
1 | recognition.addEventListener('result', function(event) {}); |
打印一下event.results(返回SpeechRecognitionResultList):
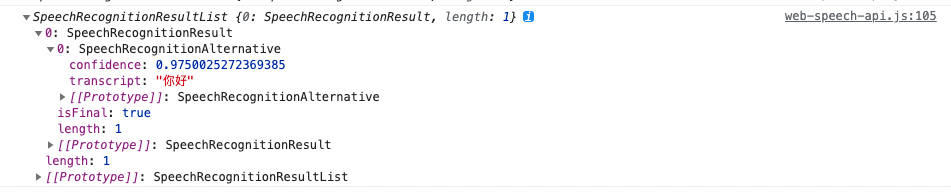
event.results[i]: 包含识别结果对象的数组。 每个数组元素对应第i个识别阶段的一个识别词event.result[i][j]: 已识别单词的第 j 个选项。 第一个元素是最有可能识别的单词。maxAlternatives此属性将设置每个结果的 SpeechRecognitionAlternatives 的最大数量。 默认值为 1。这个属性将会影响event.result[i]数组的最大长度,最多识别的单词数。event.results[i].isFinal: 表明此结果是最终结果(true)还是临时结果(false)的布尔值。event.results[i][j].transcript: 对于输入语音识别的文本event.results[i][j].confidence: 对于输入语音识别文本的置信度(值从0到1)
语音识别DEMO
语音识别可参考如下DEMO:
- github项目:Chrome-Web-Speech-API

核心代码如下:
1 | recognition = new webkitSpeechRecognition(); |
MDN示例:speech-color-changer
MDN在线体验:Speech color changer
推荐第一个,作者写了一篇文章来解读Voice to Text with Chrome Web Speech API
SpeechSynthesis

语音合成API的接口信息可参考https://wicg.github.io/speech-api/#tts-section.
完整的属性和方法可参考MDN-SpeechSynthesis、MDN-SpeechSynthesisUtterance.
1 | // 截取部分关键API接口 |
Properties
SpeechSynthesis.paused(只读):当SpeechSynthesis处于暂停状态时,返回true。SpeechSynthesis.pending(只读):当语音播放队列到目前为止保持没有说完的语音时,返回true。SpeechSynthesis.speaking(只读):当语音谈话正在进行的时候,即使SpeechSynthesis处于暂停状态,也会返回true。
Methods
SpeechSynthesis.cancel():移除所有语音谈话队列中的谈话。SpeechSynthesis.getVoices():返回当前设备所有可用声音的列表。SpeechSynthesis.pause():把SpeechSynthesis对象置为暂停状态。SpeechSynthesis.resume():把SpeechSynthesis对象置为一个非暂停状态:如果已经暂停了则继续。SpeechSynthesis.speak():添加一个utterance到语音谈话队列;它将会在其他语音谈话播放完之后播放。
需要重点注意的是SpeechSynthesis.speak()方法。在interface SpeechSynthesis中关于speak的规定是:speak(SpeechSynthesisUtterance utterance);。也就说speak方法接受的参数为SpeechSynthesisUtterance实例。
SpeechSynthesisUtterance实例属性:
- lang:获取或设置语音的语言,具体语言列表可以通过SpeechSynthesis.getVoices()获取
- pitch:获取或设置语音的音调
- rate:获取或设置语音的语速
- text:获取或设置朗读语音的文字
- voice:获取或设置用于朗读的语音
- volume:获取或设置朗读的音量
SpeechSynthesisUtterance事件可参考上面的SpeechSynthesisUtterance接口。
Event
SpeechSynthesis.onvoiceschanged:当由SpeechSynthesis.getVoices()方法返回的SpeechSynthesisVoice列表改变时触发。
语音朗读DEMO
涉及到大多数的属性和事件
对应代码库:speak-easy-synthesis
一个超级简单的小DEMO:
1 |
|




