
浅析ArrayBuffer对象(上)
浅析ArrayBuffer对象(上)
前言
ArrayBuffer对象、TypedArray视图和DataView视图是Javascript操作二进制数据的一个接口。它们都以数组的语法处理二进制数据,所以统称为二进制数组。它很像C语言的数组,允许开发者以数组下标的形式直接操作内存。
二进制数组由3类对象组成:
- ArrayBuffer对象:代表内存中的一段二进制数据,可以通过“视图”进行操作。“视图”部署了数组借口,这意味着,可以用数组的方法操作内存。
- TypedArray视图:共包含9种类型的视图。
- DataView视图:可以自定义符复合格式的视图,比如第一个字节是Uint8(无符号8位整数)、第二个和第三个字节是Int16(16位整数)、第四个字节是Float32(32位浮点数)等,还可以自定义字节序。
二进制数组并不是真正的数组,而是类似数组的对象。
TypedArray视图支持的数据类型一共9种(DataView视图支持除Uint8C以外的其他8种), 如下表所示。
| 数据类型 | 字节长度 | 含义 | 对应的C语言类型 |
|---|---|---|---|
| Int8 | 1 | 8位带符号整数 | signed char |
| Uint8 | 1 | 8位不带符号整数 | unsigned char |
| Uint8C | 1 | 8位不带符号整数(自动过滤溢出) | unsigned char |
| Int16 | 2 | 16位带符号整数 | short |
| Uint16 | 2 | 16位不带符号整数 | unsigned short |
| Int32 | 4 | 32位带符号整数 | int |
| Uint32 | 4 | 32位不带符号整数 | unsigned int |
| Float32 | 4 | 32位浮点数 | float |
| Float64 | 8 | 64位浮点数 | double |
ArrayBuffer
ArrayBuffer对象代表存储二进制数据的一段内存。它不能直接读写,只能通过视图(TypedArray视图和DataView试图)读写。
ArrayBuffer只是一串 0 和 1。它是不知道怎么拆分这个数组中各个元素的。
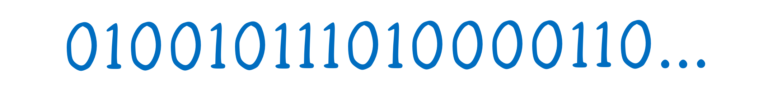
为了提供上下文信息,把 ArrayBuffer 拆分开,我们需要将它放在视图中。这些数据的视图可以添加类型化数组,并且有很多不同的类型数组可以使用。
例如,你可以使用 Int8 类型的数组,将 ArrayBuffer 分解为8位字节。
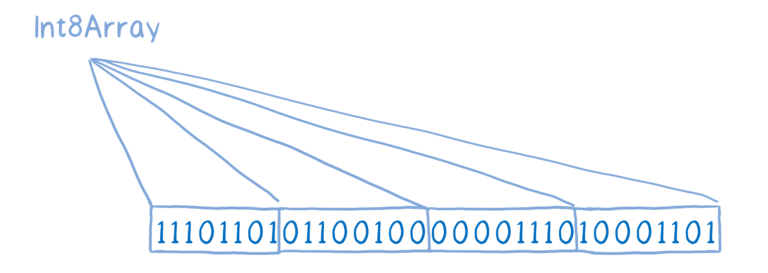
或者你可以用一个无符号的 Int16 类型数组,它可以将 ArrayBuffer 分解成16位不带符号整数。
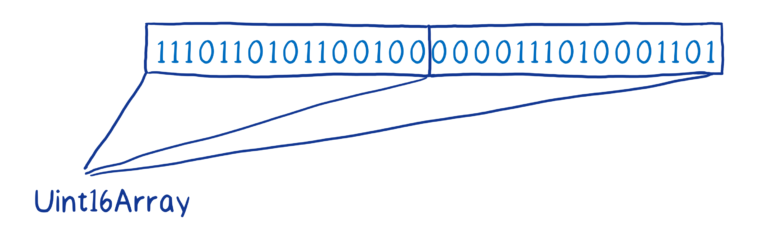
同一 buffer 上可以有多个视图,不同的视图会为相同的操作提供不同的结果。
例如,我们从这个 ArrayBuffer 的 Int8 视图获取的元素,和从它的 Uint16 视图获取的元素就是不同的值,即使它们包含完全相同的 bits。
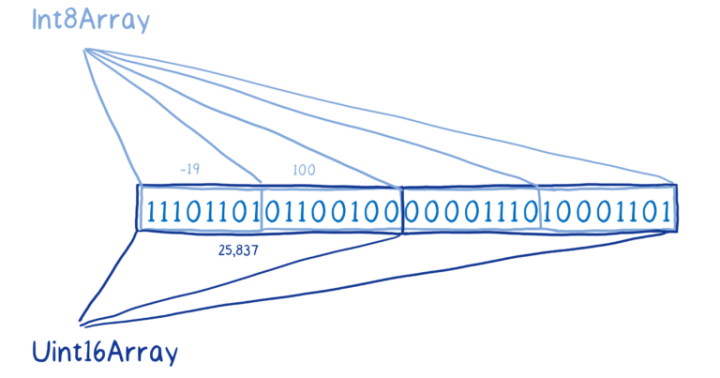
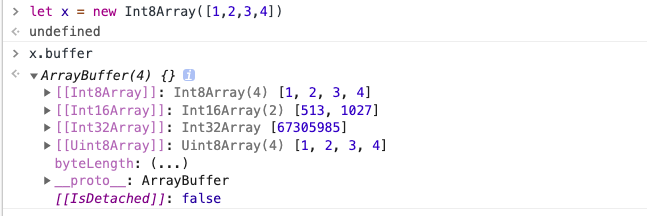
通过这种方式,ArrayBuffer 基本上就像原始内存,让你可以像使用 C 语言那样直接操作内存。
ArrayBuffer构造函数的参数是所需要的内存大小(单位为字节)。
属性和方法
- ArrayBUffer.prototype.byteLength: 返回所分配的内存区域的字节长度。
1 | let buffer = new ArrayBuffer(32); |
如果要分配的内存区域很大,有可能分配失败(因为没有那么多连续的空余内存),所以有必要检查是否分配成功。
1 | if(buffer.byteLength === n) { |
- ArrayBuffer.prototype.slice(), 该方法允许将内存区域的一部分复制生成一个新的ArrayBuffer对象。slice方法接受两个参数。第一个参数表示复制开始的字节序号(含该字节),第二个参数表示复制截止的字节序号(不含该字节)。如果省略第二个参数,则默认到ArrayBuffer对象的结尾。
1 | let buffer = new ArrayBuffer(8); |
上面的代码表示复制buffer对象的前3个字节(从0开始,到第三个字节前面结束)。
- ArrayBuffer.isView(), ArrayBuffer有一个静态方法isView,返回一个布尔值,表示参数是否为ArrayBuffer的试图实例。这个方法大致相当于判断参数是否为TypedArray实例或DataView实例。
1 | let buffer = new ArrayBuffer(8); |
TypedArray视图
由前面可以知道,ArrayBuffer对象代表内存区域。同一段内存,不同的数据有不同的解读方式,这就叫做“视图”。ArrayBuffer有两种视图,一种是TypedArray视图,另一种是DataView视图。前者的数组成员都是同一个数据类型,后者的数组成员可以是不同的数据类型。
目前,TypedArray视图一共包括9种类型,每一种类型都是一种构造函数。
- Int8Array
- Uint8Array
- Uint8ClampedArray (canvas元素专有类型)
- Int16Array
- Uint16Array
- Int32Array
- Uint32Array
- Float32Array
- Float64Array
这9种构造函数生成的数组与普通数组很像,都有length属性,都可以用方括号运算符([])获取单个元素,所有数组方法都能在其上使用。但是,TypedArray数组与普通数组并不完全一样,存在如下差异:
- TypedArray数组所有成员都是同一种类型
- TypedArray数组的成员是连续的,不会有空位
- TypedArray数组成员的默认值是0.
- TypedArray数组只是一层视图,本身不储存数据,它的数据都是存储在底层的ArrayBuffer对象中。
构造函数
- TypedArray(buffer, byteOffset = 0, length?)
同一个ArrayBuffer对象之上,可以根据不同的数据类型建立多个视图。
1 | //创建一个8字节的ArrayBuffer |
上面的代码在一段长度为8个字节的内存b之上,生成了3个视图:v1、v2和v3。这3个试图是重叠的:v1[0]是一个32位整数(4个字节),指向字节0-字节3;v2[0]是一个8位无符号整数(1个字节),指向字节2;v3[0]是一个16位整数(2个字节),指向字节2-字节3。
视图的构造函数可以接受3个参数。只有第一个是必选的,对应底层ArrayBuffer对象。
第二个参数byteOffset必须与所要建立的数据类型一致,否则会报错。
1 | let buffer = new ArrayBuffer(8); |
之所以报错是因为:带符号的16位整数需要2个字节,所以byteOffset参数必须能被2整除。
- TypedArray(length)
视图还可以不通过ArrayBuffer对象,而是直接分配内存生成。
1 | let f64a = new Float64Array(8); |
上面的代码生成了一个8个成员的Float64Array数组(64字节),然后依次对每个成员赋值。视图数组的赋值操作与普通数组别无二致。
- 构造函数的参数也可以是一个普通的数组,然后直接生成TypedArray实例。
1 | let typedArray = new Int8Array([1, 2, 3, 4]); |
这个时候TypedArray视图会重新开辟内存,不会在原数组的内存上建立视图。
TypedArray数组也可以转回普通数组:
1 | let normalArray = Array.prototype.slice.call(typedArray); |
- 构造函数还可以接受另一个人TypedArray实例作为参数。
1 | let typedArray = new Int8Array(new Int8Array([1, 1])); |
此时生成的数组只是复制了参数数组的值,对应的底层内存是不一样的。新数组会开辟一段新的内存存储空间,不会在原数组的内存之上建立视图。
如果想基于同一段内存空间构造不同的视图,可以采用下面的写法:
1 | let x = new Int8Array([1, 2]); |
数组方法
普通数组的操作方法和属性对TypedArray数组完全适用。

push/pop/concat方法不在其中。
由上图也可以看出:
- TypedArray数组也部署了Iterator接口(Symbol[iterator]), 所以可以遍历(for…of…)
- 每一种视图的构造函数都有一个
BYTES_PER_ELEMENT属性,表示这种数据类型占据的字节数 - TypedArray实例属性和方法:
- TypedArray.prototype.buffer
- TypedArray.prototype.byteLength
- TypedArray.prototype.byteOffset
- TypedArray.prototype.length
- TypedArray.prototype.set():用于复制数组(普通数组或TypedArray数组)也就是将一段内存完全复制到另一段内存。
- TypedArray.prototype.subArray():对于TypedArray数组的一部分再建立一个新的试图。
- TypedArray.prototype.slice()
此外,TypedArray数组的所有构造函数都有静态方法:of和from。
- TypedArray.of():用于将参数转为一个TypedArray实例
- TypedArray.from():接受一个可遍历的数据结构(如数组)作为参数,返回一个基于此结构的TypedArray实例
字节序
TypedArray数字只能处理小端字节序。为了解决这个问题,JavaScript引入了DataView对象,可以设定字节序。
端序又称字节序(Endianness),表示多字节中的字节排列方式。小端序是指字节的最低有效位在最高有效位之前(大端序正好与之相反),例如数字10,如果用16位二进制表示,那么它就变为0000 0000 0000 1010,换算成16进制就是000A,用小端序存储的话,该值会被表示成0A00。虽然大端序更符合人类的阅读习惯,但英特尔处理器和多数浏览器采用的都是小端序。
还是以这个图为例,内存中存储的二进制为:00000001 00000010 00000011 00000100.
对于Int16Array(占2个字节)而言,小端序读出顺序为0000001000000001 0000010000000011
1 | parseInt('0000001000000001', 2);//513 |
同理对于Int32Array(占4个字节)而言,小端序读出顺序为00000100000000110000001000000001
1 | parseInt('00000100000000110000001000000001', 2);//67305985 |
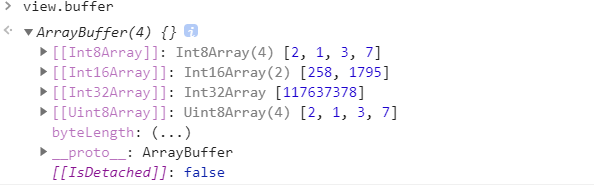
可以再从存储的角度来看一下小端序:
1 | let view = new Uint8Array([2,1,3,7]); |
view.buffer如下:
同一段内存建立Uint16Array视图:
u16[0] === 258; //true 00000001 00000010
进行赋值运算:
1 | u16[0] = 0xff05; //65285 |
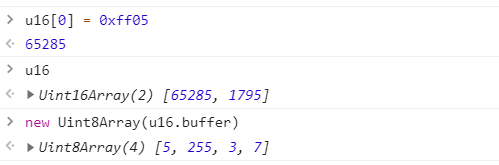
可以看出赋值运算后,字节变为:[0x05, 0xff, 0x03, 0x07]
ArrayBuffer与字符串的相互转换
ArrayBuffer转为字符串,或者字符串转为ArrayBuffer,都有一个前提,即字符串的编码方式是确定的。
1 | //ArrayBuffer转字符串 |
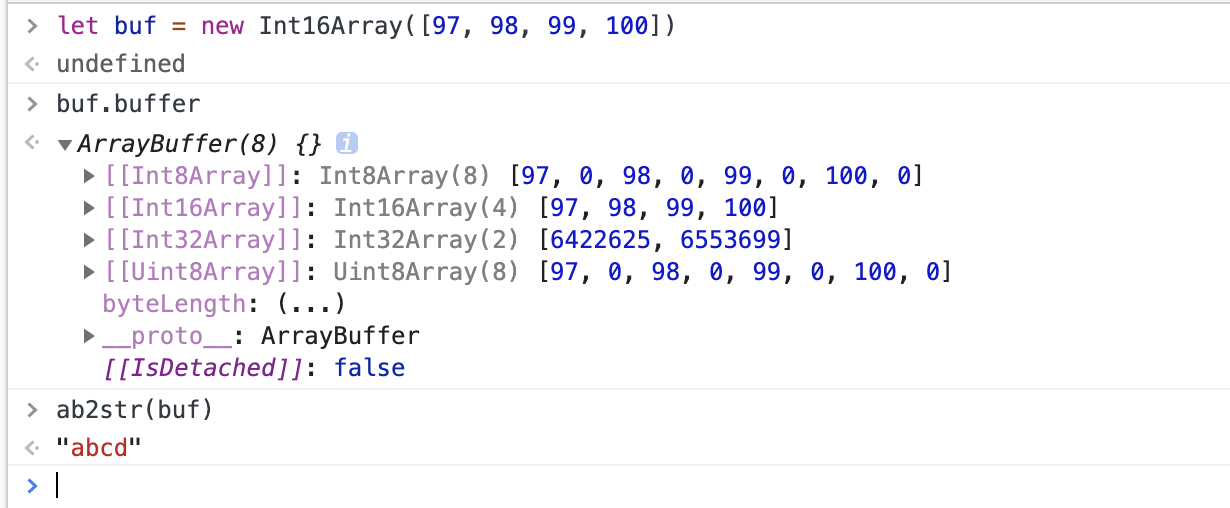
1 | //字符串转ArrayBuffer |
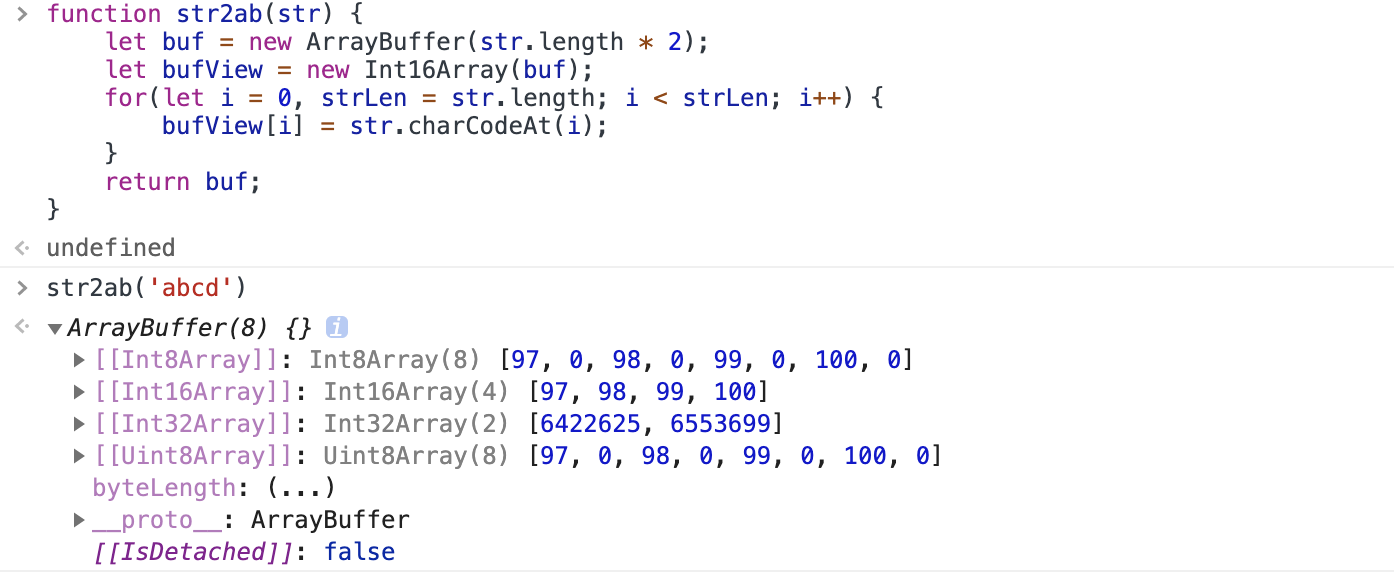
复合视图
由于视图的构造函数可以指定起始位置和长度,所以在同一段内存中可以依次存放不同类型的数据,这叫做“复合视图”。
1 | let buffer = new ArrayBuffer(24); |
DataView视图
DataView视图本身也是构造函数,接受一个ArrayBuffer对象作为参数生成视图。
DataView(ArrayBuffer, [, 字节起始位置 [, 长度]]);
例如:
1 | let buffer = new ArrayBuffer(24); |
DataView实例有一下属性,含义与TypedArray实例的同名方法相同。
- DataView.prototype.buffer:返回对应的的ArrayBuffer对象
- DataView.prototype.byteLength:返回占据的内存字节长度
- DataView.prototype.byteOffset:返回当前视图从对应的ArrayBuffer对象的哪个字节开始。
DataView实例提供8个方法读取内存:
- getInt8:读取1个字节,返回一个8位整数
- getUint8:读取1个字节,返回一个无符号的8位整数
- getInt16:读取2个字节,返回一个16位整数
- getUint16:读取2个字节,返回一个无符号的16位整数
- getInt32:读取4个字节,返回一个32位整数
- getUint32:读取4个字节,返回一个无符号的32位整数
- getFloat32:读取4个字节,返回一个32位浮点数
- getFloat64:读取8个字节,返回一个64位浮点数
这一系列get方法的参数都是一个字节序号,不可为负数,表示从哪个字节开始读取。
如果一次读取两个或两个以上字节,必须明确数据的存储方式:大端序/小端序。默认DataView的get方法使用大端序解读数据,如果需要使用小端序解读,必须在get方法的第二个参数指定true。
DataView实例提供8个方法写入内存:
- setInt8: 写入1个字节的8位整数
- setUint8: 写入1个字节的8位无符号整数
- setInt16: 写入2个字节的16位整数
- setUint16: 写入2个字节的16位无符号整数
- setInt32: 写入4个字节的32位整数
- setUint32: 写入4个字节的32位无符号整数
- setFloat32: 写入4个字节的32位浮点数
- setFloat64: 读取8个字节的64位浮点数
这一系列set方法接受两个参数:第一个是字节序号,表示从哪个字节开始写入;第二个是写入的数据。对于那些写入两个及两个以上字节的方法,需要指定第三个参数,false/undefined表示使用大端序写入,true表示使用小端序写入数据。
SharedArrayBuffer
Javascript是单线程的,web worker引入了多线程;每个线程的数据都是隔离的,通过postMeaasge()通信。
与专有工作者线程通信的方式有3种:postMessage()、MessageChannel、BroadcastChannel。具体用法会在会在后续文章‘工作者线程’中介绍。
使用工作者线程时,经常需要为它们提供某种形式的数据负载。工作者线程是独立的上下文,因此在上下文之间传输数据就会产生消耗。在JavaScript中,有三种在上下文间转移信息的方式:结构化克隆算法(structured clone algorithm)、可转移对象(transferable objects)和共享数组缓冲区(shared array buffers)。postMessage()通信就是采用的结构化克隆算法,在通过postMessage()传递对象时,浏览器会遍历该对象,并在目标上下文中生成它的一个副本。
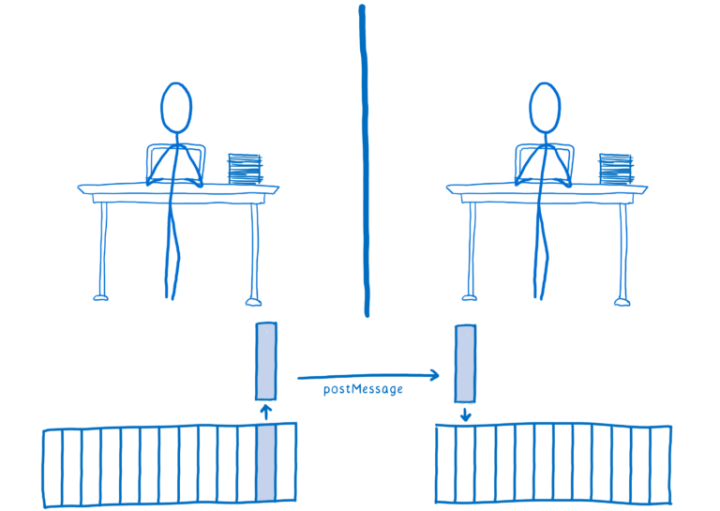
这是一个相当缓慢的过程。
对于某些数据,比如 ArrayBuffer,你还可以使用“可转移对象”。这种方式会把指定区域的内存移动到另一个 web worker 那里。
但是之前的 web worker 将不再能访问这些被转移走的内存。
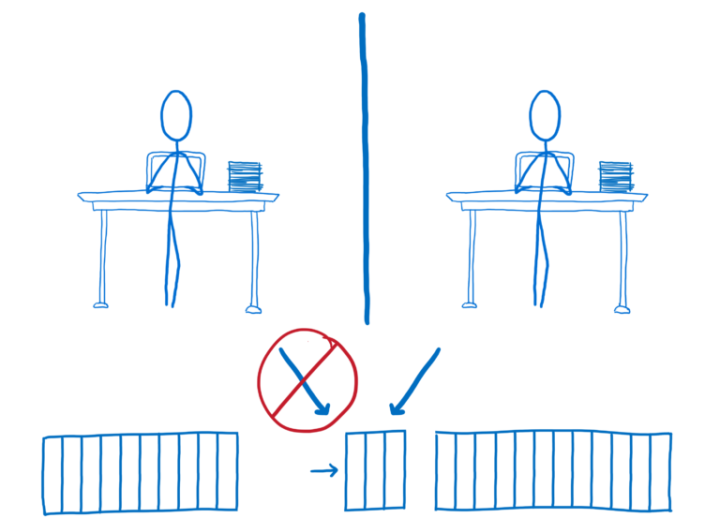
转移内存这种方式适用于某些场景,但是对于更多的高性能并行的场景,共享内存才是你真正想要的。
这就是 SharedArrayBuffers 能给你的。
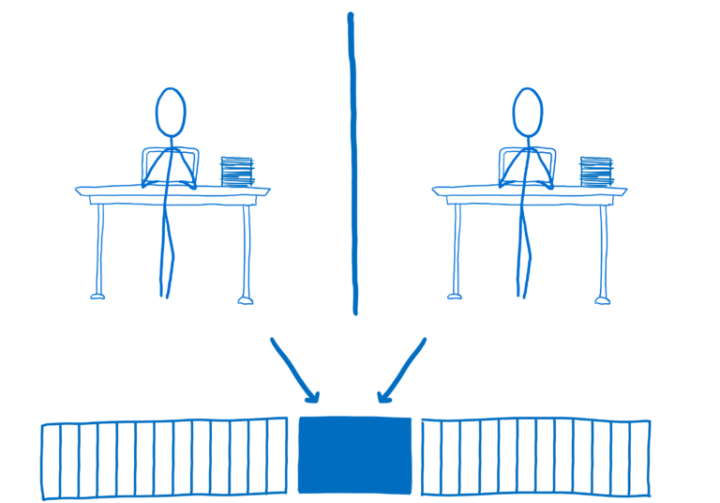
有了 SharedArrayBuffers,多个 web workers,多个线程都可以在同一块内存上读写数据。
这意味着他们不会再有使用 postMessage 时的通讯开销和延迟。
所有 web workers 都可以即时访问数据。当然,多个线程同时访问内存是有风险的,这会引起条件竞争(race conditions)问题。
为解决这个问题,Atomics API 应运而生。Atomics API 可以保证SharedArrayBuffer 上的JavaScript 操作是线程安全的。
关于线程安全可以看这篇文章,写的通俗易懂,是个大佬。如果你这样回答“什么是线程安全”,面试官都会对你刮目相看
在JS高级程序设计(第四版)中演示这一现象:
首先是线程不安全的操作:
1 | const workerScript = ` |
这里,每个工作者线程都顺序执行了100 万次加操作,每次都读取共享数组的索引、执行一次加操作,然后再把值写回数组索引。在所有工作者线程读/写操作交织的过程中就会发生资源争用。例如:
- 线程A读取值1;
- 线程B读取到值1;
- 线程A加1并将2写回数组
- 线程B仍然使用陈旧的数组值1,同样把2写回数组。
要解决这个问题,就需要Atomics对象来改写成线程安全的加操作:
1 | const workerScript = ` |
Atomics对象
Atomics对象提供多种方法如下:
原子读写
- Atomics.store(array, index, value)
- Atomics.load(array, index)
store()方法用来向共享内存写入数据,load()方法用来从共享内存中读出数据。比起直接的读写操作,它们的好处是保证了读写操作的原子性。
什么叫“原子性操作”呢?现代编程语言中,一条普通的命令被编译器处理以后会变成多条机器指令。如果是单线程运行,这是没有问题的。多线程环境并且共享内存的时候,就会出问题,因为这一组机器指令的运行期间可能会插入其他线程的指令,从而导致运行结果出错。
i++为什么不是原子操作?
它相当于3个原子性操作:
- 读取变量的值;
- 将变量i的值加一;
- 将结果写入变量i中。
- Atomics.wait()
- Atomics.wake()
这两个方法还要再研究研究
运算方法
- Atomics.add(array, index, value)
- Atomics.sub(array, index, value)
- Atomics.and(array, index, value)
- Atomics.or(array, index, value)
- Atomics.xor(array, index, value)
以Atomics.add(array, index, value)为例:将value加到array[index]中,返回array[index]的旧值。其他的方法同理(减运算、位与运算、位或运算、位异或运算)
其他方法
- Atomics.exchange(array, index, value) 设置array[index]的值,返回旧的值
- Atomics.compareExchange(array, index, oldValue, value) 如果array[index]等于oldValue,就写入value,返回oldValue。
总结
本文从ArrayBuffer入手,因为ArrayBuffer不可以直接读写,进而引出视图(TypedArray/DataView)。最后介绍了共享内存SharedArrayBuffer;由于多个线程同时访问共享内存,会带来竞争风险,所以引入了Atomics对象,保证操作的原子性,进而保证线程安全。




