
How JavaScript works - Event loop and the rise of Async programming + 5 ways to better coding with async/await
How JavaScript works - Event loop and the rise of Async programming + 5 ways to better coding with async/await
Javascript工作原理:事件循环及异步编程的出现 + 5种更好的async/await编程方式
This time we’ll expand on our first post by reviewing the drawbacks to programming in a single-threaded environment and how to overcome them using the Event Loop and async/await in order to build stunning JavaScript UIs. As the tradition goes, at the end of the article we’ll share 5 tips on how to write cleaner code with async/await.
现在,我们将会通过回顾单线程环境下编程的弊端及以及如何使用事件循环和async/await来克服这些缺点以创建令人惊叹的 JavaScript 交互界面来展开第一篇文章。老规矩,我们将会在本章末尾分享 5 条利用 async/await 编写更简洁代码的小技巧。
Why having a single thread is a limitation?
单线程的局限性
In the first post we launched, we pondered over the question what happens when you have function calls in the Call Stack that take a huge amount of time to be processed.
在第一篇文章的开头,我们考虑了一个问题即当调用栈中含有需要长时间运行的函数调用的时候会发生什么。
Imagine, for example, a complex image transformation algorithm that’s running in the browser.
譬如,试想下,在浏览器中运行着一个复杂的图片转化算法。
While the Call Stack has functions to execute, the browser can’t do anything else — it’s being blocked. This means that the browser can’t render, it can’t run any other code, it’s just stuck. And here comes the problem — your app UI is no longer efficient and pleasing.
恰好此时调用栈中有函数需要执行,此时浏览器将会被阻塞,它不能够做其它任何事情。这意味着,浏览器会没有响应,不能够进行渲染和运行其它代码。这将会带来问题-程序界面将不再高效和令人愉悦。
Your app is stuck.
程序没有响应。
In some cases, this might not be such a critical issue. But hey — here’s an even bigger problem. Once your browser starts processing too many tasks in the Call Stack, it may stop being responsive for a long time. At that point, a lot of browsers would take action by raising an error, asking whether they should terminate the page:
在某些情况下,这或许没什么大不了的。但是,这可能会造成更加严重的问题。一旦浏览器在调用栈中同时运行太多的任务的时候,浏览器会很长时间停止响应。到了那个时候,大多数浏览器会抛出一个错误,询问你是否关闭网页。
It’s ugly, and it completely ruins your UX:
这很丑陋且它完全摧毁了程序的用户体验。

The building blocks of a JavaScript program
JavaScript程序组件
You may be writing your JavaScript application in a single .js file, but your program is almost certainly comprised of several blocks, only one of which is going to execute now, and the rest will execute later. The most common block unit is the function.
你可能会在单一的 .js 文件中书写 JavaScript 程序,但是程序是由多个代码块组成的,当前只有一个代码块在运行,其它代码块将在随后运行。最常见的块状单元是函数。
The problem most developers new to JavaScript seem to have is understanding that later doesn’t necessarily happen strictly and immediately after now. In other words, tasks that cannot complete now are, by definition, going to complete asynchronously, which means you won’t have the above-mentioned blocking behavior as you might have subconsciously expected or hoped for.
大多数 JavaScript 新手有可能需要理解的问题即之后运行表示的是并不是必须严格且立即在现在之后执行。换句话说即,根据定义,现在不能够运行完毕的任务将会异步完成,这样你就不会不经意间遇到以上提及的 UI 阻塞行为。
Let’s take a look at the following example:
看如下代码:
1 | // ajax(..) is some arbitrary Ajax function given by a library |
You’re probably aware that standard Ajax requests don’t complete synchronously, which means that at the time of code execution the ajax(..) function does not yet have any value to return back to be assigned to a response variable.
可能你已经知道标准的 ajax 请求不会完全同步执行完毕,意即在代码运行阶段,ajax(..) 函数不会返回任何值给 response 变量。
A simple way of “waiting” for an asynchronous function to return its result is to use a function called callback:
获得异步函数返回值的一个简单方法是使用回调函数。
1 | ajax('https://example.com/api', function(response) { |
Just a note: you can actually make synchronous Ajax requests. Never, ever do that. If you make a synchronous Ajax request, the UI of your JavaScript app will be blocked — the user won’t be able to click, enter data, navigate, or scroll. This would prevent any user interaction. It’s a terrible practice.
只是要注意一点:即使可以也永远不要发起同步 ajax 请求。如果发起同步 ajax 请求,JavaScript 程序的 UI 将会被阻塞-用户不能够点击,输入数据,跳转或者滚动。这将会冻结任何用户交互体验。这是非常糟糕。
This is how it looks like, but please, never do this — don’t ruin the web:
以下示例代码,但请别这样做,这会毁掉网页:
1 | // This is assuming that you're using jQuery |
We used an Ajax request just as an example. You can have any chunk of code execute asynchronously.
我们以 Ajax 请求为例。你可以异步执行任意代码。
This can be done with the setTimeout(callback, milliseconds) function. What the setTimeout function does is to set up an event (a timeout) to happen later. Let’s take a look:
你可以使用
setTimeout(callback, milliseconds)函数来异步执行代码。setTimeout函数会在之后的某个时刻触发事件(定时器)。如下代码:
1 | function first() { |
The output in the console will be the following:
控制台输出如下:
1 | first |
What is the Event Loop?
事件循环详解
We’ll start with a somewhat of an odd claim — despite allowing async JavaScript code (like the setTimeout we just discussed), until ES6, JavaScript itself has actually never had any direct notion of asynchronicity built into it. The JavaScript engine has never done anything more than executing a single chunk of your program at any given moment.
我们将会以一个有些让人费解的问题开始-尽管允许异步执行 JavaScript 代码(比如之前讨论的
setTimetout),但是直到 ES6,实际上 JavaScript 本身并没有集成任何直接的异步编程概念。JavaScript 引擎只允许在任意时刻执行单个的程序片段。
For more details on how JavaScript engines work (Google’s V8 specifically), check one of our previous articles on the topic.
可以查看之前的文章来了解 JavaScript 引擎的工作原理。
So, who tells the JS Engine to execute chunks of your program? In reality, the JS Engine doesn’t run in isolation — it runs inside a hosting environment, which for most developers is the typical web browser or Node.js. Actually, nowadays, JavaScript gets embedded into all kinds of devices, from robots to light bulbs. Every single device represents a different type of hosting environment for the JS Engine.
那么, JS 引擎是如何执行程序片段的呢?实际上,JS 引擎并不是隔离运行的-它运行在一个宿主环境中,对大多数开发者来说是典型的 web 浏览器或者 Node.js。实际上,现在 JavaScript 广泛应用于从机器到电灯泡的各种设备之中。每个设备代表了 JS 引擎的不同类型的宿主环境。
The common denominator in all environments is a built-in mechanism called the event loop, which handles the execution of multiple chunks of your program over time, each time invoking the JS Engine.
所有宿主环境都含有一个被称为事件循环的内置机制,随着时间的推移,事件循环会执行程序中多个代码片段,每次都会调用 JS 引擎。
This means that the JS Engine is just an on-demand execution environment for any arbitrary JS code. It’s the surrounding environment that schedules the events (the JS code executions).
这意味着 JS 引擎只是任意 JS 代码的按需执行环境。这是一个封闭的环境,在其中进行事件的调度(运行JS 代码)。
So, for example, when your JavaScript program makes an Ajax request to fetch some data from the server, you set up the “response” code in a function (the “callback”), and the JS Engine tells the hosting environment:
所以,打个比方,当 JavaScript 程序发起 Ajax 请求来从服务器获得数据,你在回调函数中书写 “response” 代码,JS 引擎会告诉宿主环境:
“Hey, I’m going to suspend execution for now, but whenever you finish with that network request, and you have some data, please call this function back.”
“嘿,我现在要挂起执行了,现在当你完成网络请求的时候且返回了数据,请执行回调函数。”
The browser is then set up to listen for the response from the network, and when it has something to return to you, it will schedule the callback function to be executed by inserting it into the event loop.
之后浏览器会监听从网络中返回的数据,当有数据返回的时候,它会通过把回调函数插入事件循环以便调度执行。
Let’s look at the below diagram:
让我们看下如下图示:
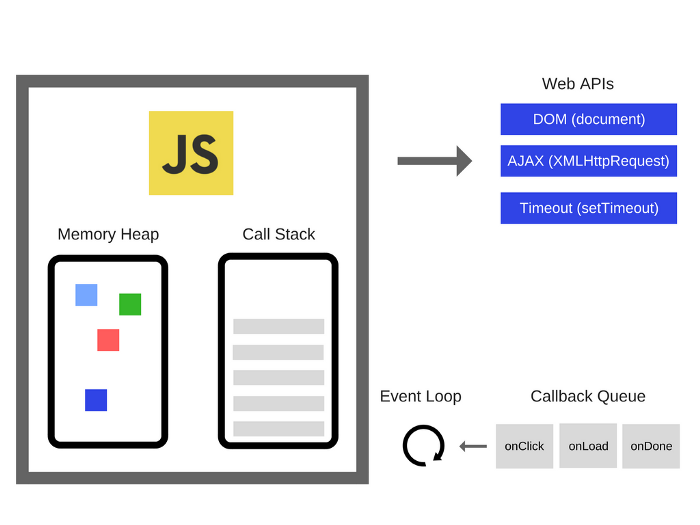
You can read more about the Memory Heap and the Call Stack in our previous article.
你可以在之前的文章中阅读更多关于动态内存管理和调用栈的信息。
And what are these Web APIs? In essence, they are threads that you can’t access, you can just make calls to them. They are the pieces of the browser in which concurrency kicks in. If you’re a Node.js developer, these are the C++ APIs.
什么是网页 API ?本质上,你没有权限访问这些线程,你只能够调用它们。它们是浏览器自带的,且可以在浏览器中进行并发操作。如果你是个 Node.js 开发者,这些是 C++ APIs。
So what is the event loop after all?
所以什么是事件循环呢?
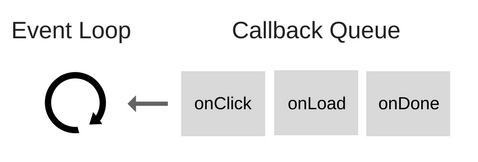
The Event Loop has one simple job — to monitor the Call Stack and the Callback Queue. If the Call Stack is empty, the Event Loop will take the first event from the queue and will push it to the Call Stack, which effectively runs it.
事件循环只有一项简单的工作-监测调用栈和回调队列。如果调用栈是空的,它会从回调队列中取得第一个事件然后入栈,并有效地执行该事件。
Such an iteration is called a tick in the Event Loop. Each event is just a function callback.
事件循环中的这样一次遍历被称为一个 tick。每个事件就是一个回调函数。
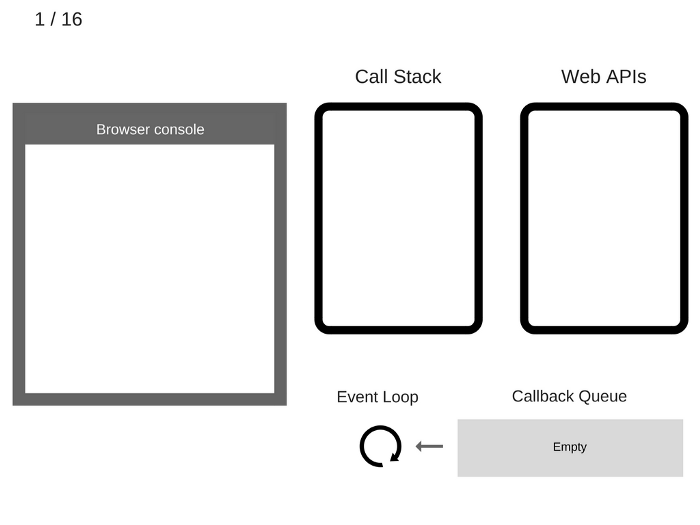
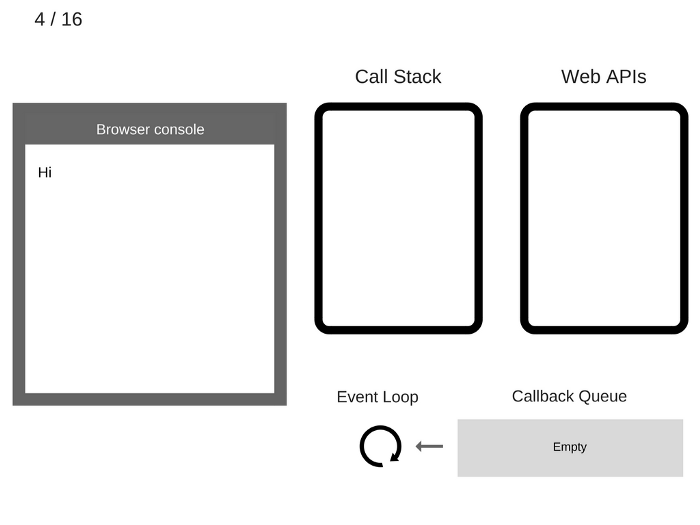
1 | console.log('Hi'); |
Let’s “execute” this code and see what happens:
让我们执行这段代码,然后看看会发生什么:
The state is clear. The browser console is clear, and the Call Stack is empty.
空状态。浏览器控制台是空的,调用栈也是空的。
console.log('Hi')is added to the Call Stack.console.log('Hi')入栈。
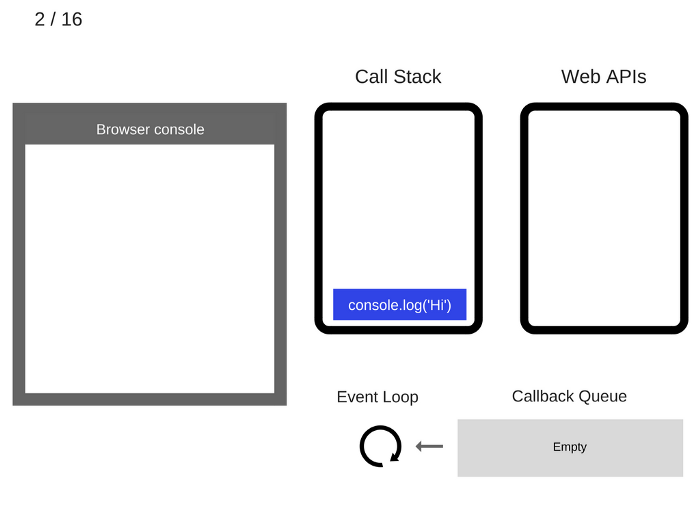
console.log('Hi')is executed.执行
console.log('Hi')。

console.log('Hi')is removed from the Call Stack.console.log('Hi')出栈
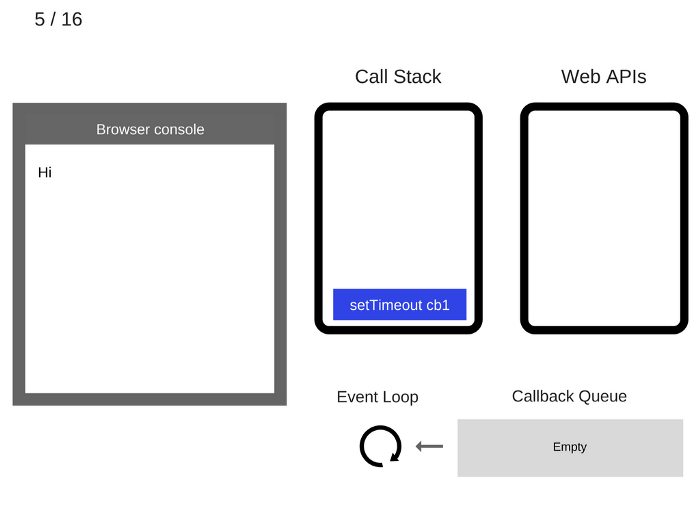
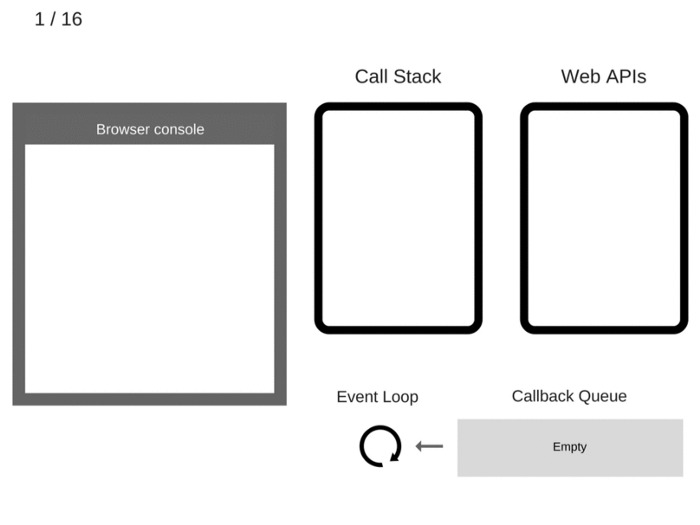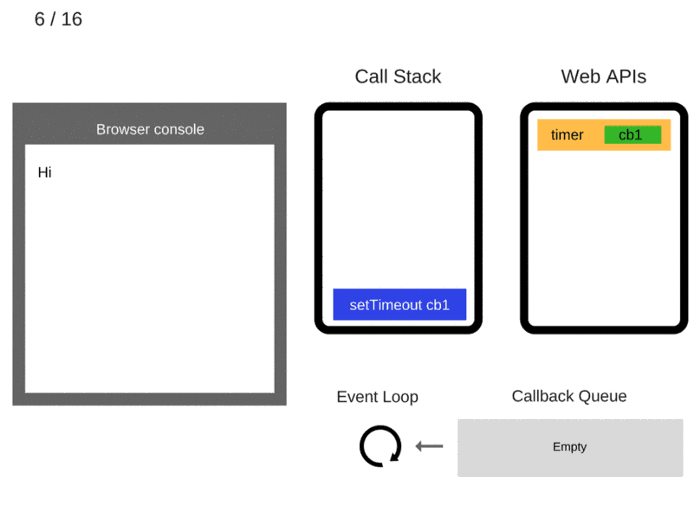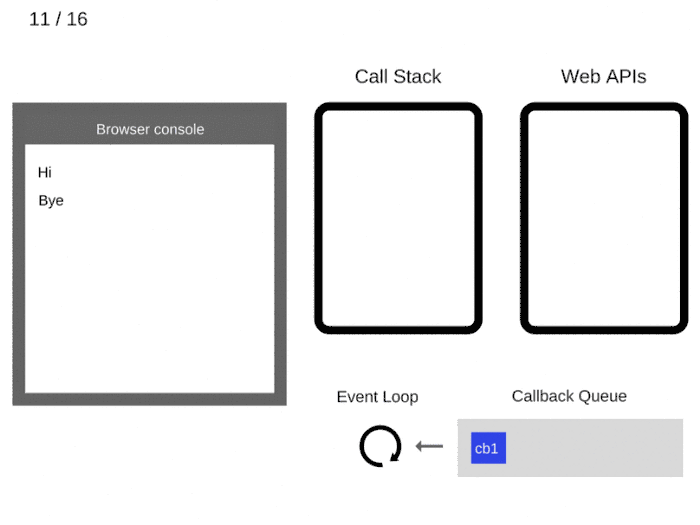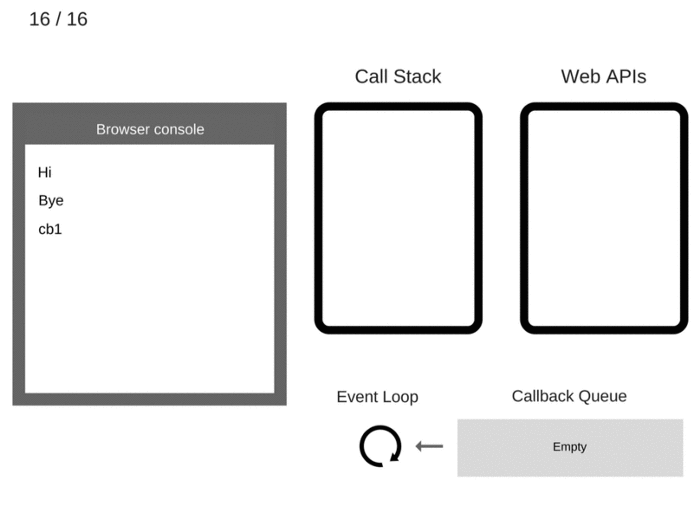
setTimeout(function cb1() { ... })is added to the Call Stack.setTimeout(function cb1() { ... })入栈。
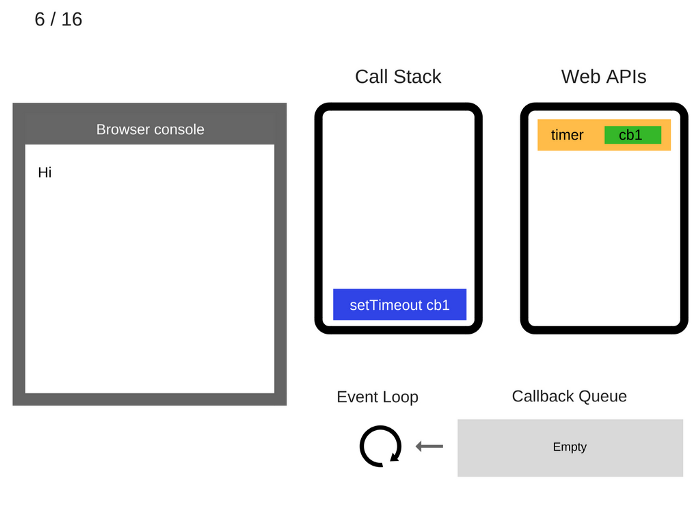
setTimeout(function cb1() { ... })is executed. The browser creates a timer as part of the Web APIs. It is going to handle the countdown for you.执行
setTimeout(function cb1() { ... }),浏览器创建定时器作为网页 API 的一部分并将会为你处理倒计时。
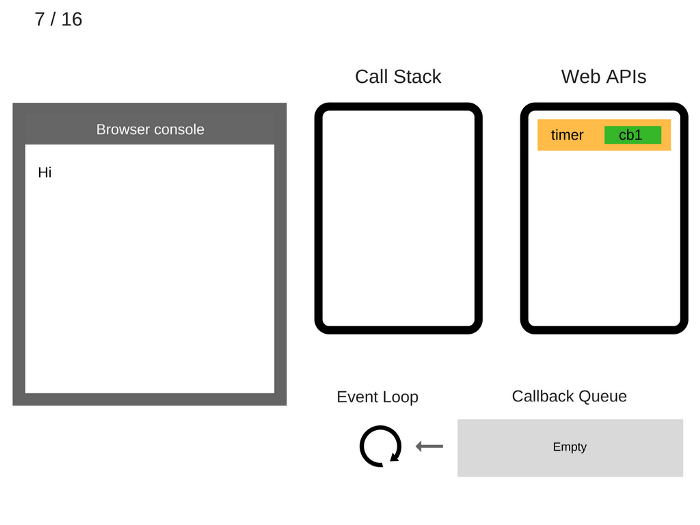
The
setTimeout(function cb1() { ... })itself is complete and is removed from the Call Stack.setTimeout(function cb1() { ... })执行完毕并出栈。
console.log('Bye')is added to the Call Stack.console.log('Bye')入栈。
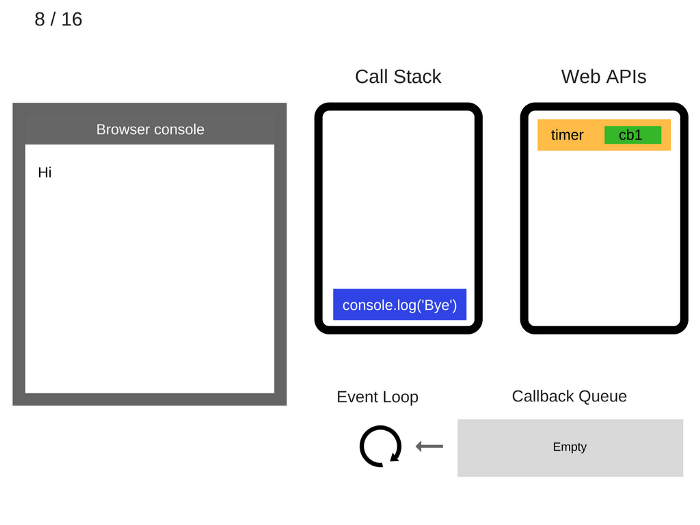
console.log('Bye')is executed.执行
console.log('Bye')。

console.log('Bye')is removed from the Call Stack.console.log('Bye')出栈。
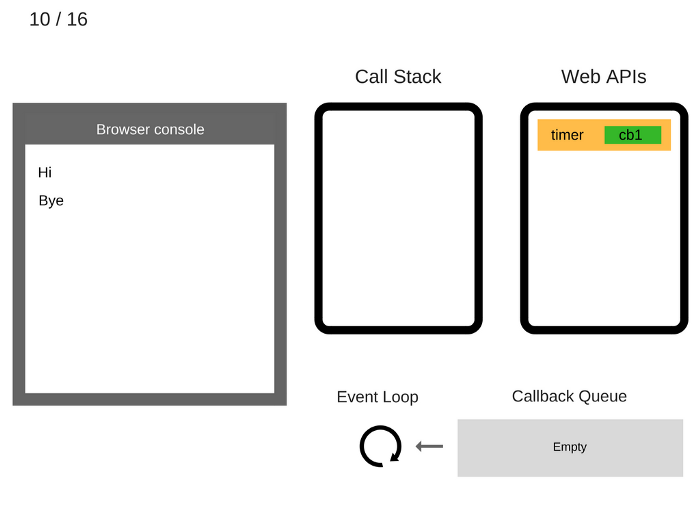
After at least 5000 ms, the timer completes and it pushes the cb1 callback to the Callback Queue.
至少 5 秒之后,定时器结束运行并把
cb1回调添加到回调队列。

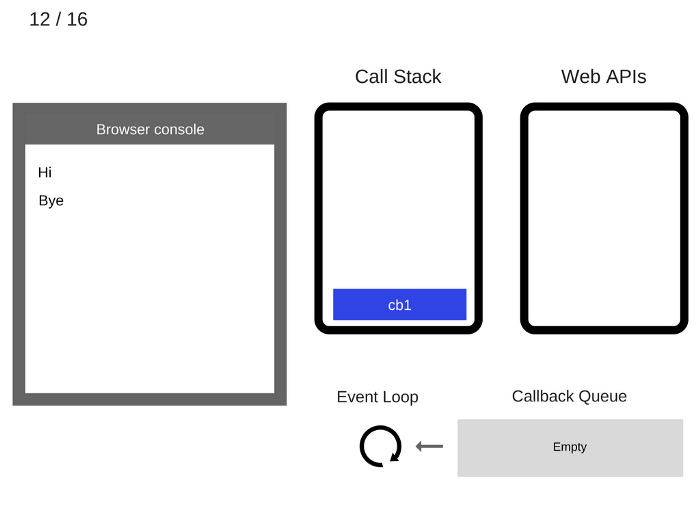
The Event Loop takes
cb1from the Callback Queue and pushes it to the Call Stack.事件循环从回调队列中获得
cb1函数并且将其入栈。
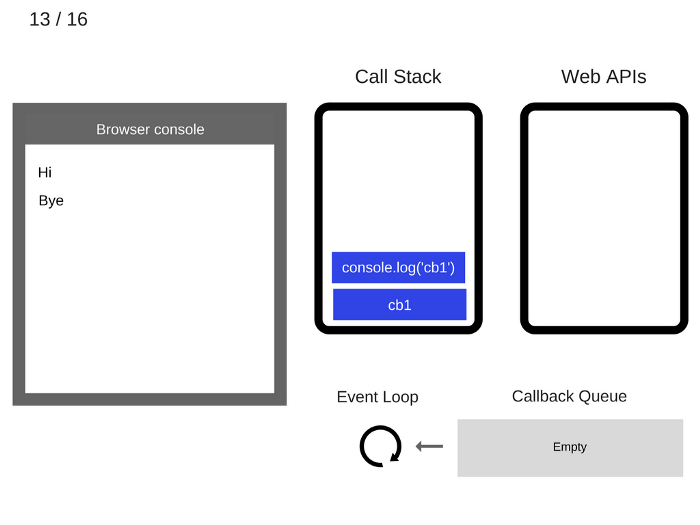
cb1is executed and addsconsole.log('cb1')to the Call Stack.运行
cb1函数并将console.log('cb1')入栈。
console.log('cb1')is executed.执行
console.log('cb1')。
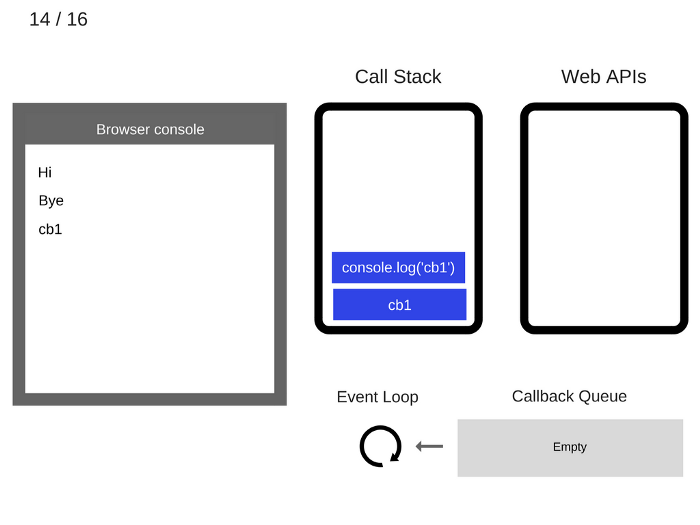
console.log('cb1')is removed from the Call Stack.console.log('cb1')出栈。

cb1is removed from the Call Stack.cb1出栈。

A quick recap:
录像快速回放:
It’s interesting to note that ES6 specifies how the event loop should work, meaning that technically it’s within the scope of the JS engine’s responsibilities, which is no longer playing just a hosting environment role. One main reason for this change is the introduction of Promises in ES6 because the latter require access to a direct, fine-grained control over scheduling operations on the event loop queue (we’ll discuss them in a greater detail later).
令人感兴趣的是,ES6 规定事件循环如何工作的,这意味着从技术上讲,它在 JS 引擎负责的范围之内,而 JS 引擎将不再只是扮演着宿主环境的角色。ES6 中 Promise 的出现是导致改变的主要原因之一,因为 ES6 要求有权限直接细粒度地控制事件循环队列中的调度操作(之后会深入探讨)。
How setTimeout(…) works
setTimeout(…) 工作原理
It’s important to note that setTimeout(…) doesn’t automatically put your callback on the event loop queue. It sets up a timer. When the timer expires, the environment places your callback into the event loop, so that some future tick will pick it up and execute it. Take a look at this code:
需要注意的是
setTimeout(…)并没有自动把回调添加到事件循环队列。它创建了一个定时器。当定时器过期,宿主环境会把回调函数添加至事件循环队列中,然后,在未来的某个 tick 取出并执行该事件。查看如下代码:
1 | setTimeout(myCallback, 1000); |
That doesn’t mean that myCallback will be executed in 1,000 ms but rather that, in 1,000 ms, myCallback will be added to the event loop queue. The queue, however, might have other events that have been added earlier — your callback will have to wait.
这并不意味着 1 秒之后会执行
myCallback回调而是在 1 秒后将其添加到回调队列。然而,该队列有可能在之前就添加了其它的事件-所以回调就会被阻塞。
There are quite a few articles and tutorials on getting started with async code in JavaScript that suggest doing a setTimeout(callback, 0). Well, now you know what the Event Loop does and how setTimeout works: calling setTimeout with 0 as a second argument just defers the callback until the Call Stack is clear.
有相当一部分的文章和教程开始会建议你使用
setTimeout(callback, 0)来书写 JavaScript 异步代码。那么,现在你明白了事件循环和 setTimeout 的原理:调用setTimeout把其第二个参数设置为 0 表示延迟执行回调直到调用栈被清空。
Take a look at the following code:
查看如下代码:
1 | console.log('Hi'); |
Although the wait time is set to 0 ms, the result in the browser console will be the following:
虽然定时时间设定为 0, 但是控制台中的结果将会如下显示:
1 | Hi |
What are Jobs in ES6 ?
ES6 作业概念(微任务)
A new concept called the “Job Queue” was introduced in ES6. It’s a layer on top of the Event Loop queue. You are most likely to bump into it when dealing with the asynchronous behavior of Promises (we’ll talk about them too).
ES6 介绍了一个被称为『作业队列』的概念。它位于事件循环队列的顶部。你极有可能在处理 Promises(之后会介绍) 的异步行为的时候无意间接触到这一概念。
We’ll just touch on the concept now so that when we discuss async behavior with Promises, later on, you understand how those actions are being scheduled and processed.
现在我们将会接触这个概念,以便当讨论 Promises 的异步行为之后,理解如何调度和处理这些行为。
Imagine it like this: the Job Queue is a queue that’s attached to the end of every tick in the Event Loop queue. Certain async actions that may occur during a tick of the event loop will not cause a whole new event to be added to the event loop queue, but will instead add an item (aka Job) to the end of the current tick’s Job queue.
像这样想象一下:作业队列是附加于事件循环队列中每个 tick 末尾的队列。事件循环的一个 tick 所产生的某些异步操作不会导致添加全新的事件到事件循环队列中,但是反而会在当前 tick 的作业队列末尾添加一个作业项。
This means that you can add another functionality to be executed later, and you can rest assured that it will be executed right after, before anything else.
这意味着,你可以添加延时运行其它功能并且你可以确保它会在其它任何功能之前立刻执行。
A Job can also cause more Jobs to be added to the end of the same queue. In theory, it’s possible for a Job “loop” (a Job that keeps adding other Jobs, etc.) to spin indefinitely, thus starving the program of the necessary resources needed to move on to the next event loop tick. Conceptually, this would be similar to just expressing a long-running or infinite loop (like while (true) ..) in your code.
一个作业还可能导致更多作业添加到同一队列的末尾。从理论上讲,作业“循环”(一个不断添加其他作业的作业)可能无限期地循环,从而使程序无法继续进行下一个事件循环。从概念上讲,这类似于在代码中只表达一个长时间运行的或无限的死循环(如’while(true)`..)。
Jobs are kind of like the setTimeout(callback, 0) “hack” but implemented in such a way that they introduce a much more well-defined and guaranteed ordering: later, but as soon as possible.
作业是有些类似于
setTimeout(callback, 0)这样的小技巧,但是是以这样的方式实现的,它们拥有明确定义和有保证的执行顺序:之后且尽快地执行。
Callbacks
回调
As you already know, callbacks are by far the most common way to express and manage asynchronicity in JavaScript programs. Indeed, the callback is the most fundamental async pattern in the JavaScript language. Countless JS programs, even very sophisticated and complex ones, have been written on top of no other async foundation than the callback.
正如你已知的那样,回调函数是 JavaScript 程序中用来表示和进行异步操作最常见的方法。的确,回调是 JavaScript 语言中最为重要的异步模式。无数的 JS 程序,甚至非常复杂的那些,都是建立在回调函数之上的。
Except that callbacks don’t come with no shortcomings. Many developers are trying to find better async patterns. It’s impossible, however, to effectively use any abstraction if you don’t understand what’s actually under the hood.
回调并不是没有缺点(如, callback hell)。许多开发者试图找到更好的异步模式。然而,如果你不理解底层的原理而想要高效地使用任何抽象化的语法是不可能的。
In the following chapter, we’ll explore couple of these abstractions in-depth to show why more sophisticated async patterns (that will be discussed in subsequent posts) are necessary and even recommended.
在接下来的章节中,我们将会深入探究这些抽象语法并理解更复杂的异步模式的必要性。
Nested Callbacks
嵌套回调
Look at the following code:
查看一下示例
1 | listen('click', function (e){ |
We’ve got a chain of three functions nested together, each one representing a step in an asynchronous series.
我们有三个链式嵌套函数,每个函数代表一个异步操作。
This kind of code is often called a “callback hell”. But the “callback hell” actually has almost nothing to do with the nesting/indentation. It’s a much deeper problem than that.
这类代码通常被称为『回调地狱』。但是,实际上『回调地狱』和代码嵌套及缩进没有任何关系。这是一个更加深刻的问题。
First, we’re waiting for the “click” event, then we’re waiting for the timer to fire, then we’re waiting for the Ajax response to come back, at which point it might get all repeated again.
首先,我们监听点击事件,然后,等待定时器执行,最后等待 Ajax 返回数据,在 Ajax 返回数据的时候,可以重复执行这一过程。
At first glance, this code may seem to map its asynchrony naturally to sequential steps like:
乍一眼看上去,可以上把以上具有异步特性的代码拆分为按步骤执行的代码,如下所示:
1 | listen('click', function (e) { |
Then we have:
之后:
1 | setTimeout(function(){ |
Then later we have:
再后来:
1 | ajax('https://api.example.com/endpoint', function (text){ |
And finally:
最后:
1 | if (text == "hello") { |
So, such a sequential way of expressing your async code seems a lot more natural, doesn’t it? There must be such a way, right?
因此,以这样顺序执行的方式来表示异步代码看起来一气呵成,应该有这样的方法吧?
Promises
Take a look at the following code:
查看一下代码:
1 | var x = 1; |
It’s all very straightforward: it sums the values of x and y and prints it to the console. What if, however, the value of x or y was missing and was still to be determined? Say, we need to retrieve the values of both x and y from the server, before they can be used in the expression. Let’s imagine that we have a function loadX and loadY that respectively load the values of x and y from the server. Then, imagine that we have a function sum that sums the values of x and y once both of them are loaded.
这个很直观:计算出
x和y的值然后在控制台打印出来。但是,如果x或者y的初始值是不存在的且不确定的呢?假设,在表达式中使用x和y之前,我们需要从服务器得到x和y的值。想象下,我们拥有函数loadX和loadY分别从服务器获取 x 和 y 的值。然后,一旦获得x和y的值,就可以使用sum函数计算出和值。
It could look like this (quite ugly, isn’t it):
类似如下这样:
1 | function sum(getX, getY, callback) { |
There is something very important here — in that snippet, we treated x and y as future values, and we expressed an operation sum(…) that (from the outside) did not care whether x or y or both were or weren’t available right away.
在这段代码中需要注意的是:
x和y是未来值,我们用sum(..)(从外部)来计算来两值之和,但是并没有关注x和y是否马上同时有值。
Of course, this rough callbacks-based approach leaves much to be desired. It’s just a first tiny step towards understanding the benefits of reasoning about future values without worrying about the time aspect of when they will be available.
当然,这个粗糙的基于回调的技术还有很多需要改进的地方。这只是向理解推出未来值而不用担心何时有返回值的好处迈出的一小步。
Promise Value
Promise 值
Let’s just briefly glimpse at how we can express the x + y example with Promises:
让我们简略地看一下
x+y这个例子的 Promises 版本 :
1 | function sum(xPromise, yPromise) { |
There are two layers of Promises in this snippet.
以上代码片段含有两种层次的 Promise。
fetchX() and fetchY() are called directly, and the values they return (promises!) are passed to sum(...). The underlying values these promises represent may be ready now or later, but each promise normalizes its behavior to be the same regardless. We reason about x and y values in a time-independent way. They are future values, period.
fetchX()和fetchY()都是直接调用,它们的返回值(promises!)都被传入sum(…)作为参数。虽然这些 promises 的 返回值也许会在现在或之后返回,但是无论如何每个 promise 都具有相同的异步行为。我们可以认为x和y是与时间无关的值。暂时称他们为未来值。
The second layer is the promise that sum(...) creates (via Promise.all([ ... ])) and returns, which we wait on by calling then(...). When the sum(...) operation completes, our sum future value is ready and we can print it out. We hide the logic for waiting on the x and y future values inside of sum(...).
第二层次的 Promise 是由
sum(...)(通过Promise.all([...]))所创建和返回的,然后通过调用then(...)来等待promise的返回值。当sun(...)运行结束,返回 sum 未来值然后就可以打印出来。我们在sum(…)内部隐藏了等待未来值x和y的逻辑。
Note: Inside sum(…), the Promise.all([ … ]) call creates a promise (which is waiting on promiseX and promiseY to resolve). The chained call to .then(...) creates another promise, which the return values[0] + values[1] line immediately resolves (with the result of the addition). Thus, the then(...) call we chain off the end of the sum(...) call — at the end of the snippet — is actually operating on that second promise returned, rather than the first one created by Promise.all([ ... ]). Also, although we are not chaining off the end of that second then(...), it too has created another promise, had we chosen to observe/use it. This Promise chaining stuff will be explained in much greater detail later in this chapter.
注意:在
sum(…)内部,Promise.all([ … ])创建了一个 promise(在等待promiseX和promiseY解析之后)。链式调用.then(…)创建了另一个 promise,该 promise 会由代码values[0] + values[1]立刻进行解析(返回相加结果)。因此,在代码片段的末尾即sum(…)的末尾链式调用then(…)-实际上是在操作第二个返回的 promise 而不是第一个由Promise.all([ ... ])创建返回的 promise。同样地,虽然我们没有在第二个then(…)之后进行链式调用,但是它也创建了另一个 promise,我们可以选择观察/使用该 promise。我们将会在本章的随后内容中进行详细地探讨 promise 的链式调用相关。
With Promises, the then(...) call can actually take two functions, the first for fulfillment (as shown earlier), and the second for rejection:
在 Promises 中,实际上
then(…)函数可以传入两个函数作为参数,第一个函数是成功函数,第二个是失败函数。
1 | sum(fetchX(), fetchY()) |
If something went wrong when getting x or y, or something somehow failed during the addition, the promise that sum(...) returns would be rejected, and the second callback error handler passed to then(...) would receive the rejection value from the promise.
当获取
x或者y出现错误或者计算和值的时候出现错误,sum(…)返回的 promise 将会失败,并将promise的失败原因(拒绝值)传递给then(...)的第二个回调错误处理程序。
Because Promises encapsulate the time-dependent state — waiting on the fulfillment or rejection of the underlying value — from the outside, the Promise itself is time-independent, and thus Promises can be composed (combined) in predictable ways regardless of the timing or outcome underneath.
因为 Promise 封装与时间相关的状态—等待外部成功或失败的返回值——所以 Promise 本身是与时间无关的,因此 Promise 可以以可预测的方式组合(合并),而不用关心时序或者返回结果。
Moreover, once a Promise is resolved, it stays that way forever — it becomes an immutable value at that point — and can then be observed as many times as necessary.
此外,一旦 Promise 解析完成,它就会一直保持不可变的状态且可以被随意观察。
It’s really useful that you can actually chain promises:
链式调用 promise 真的很管用:
1 | function delay(time) { |
Calling delay(2000) creates a promise that will fulfill in 2000ms, and then we return that from the first then(...) fulfillment callback, which causes the second then(...)‘s promise to wait on that 2000ms promise.
调用
delay(2000)创建一个将在 2 秒后返回成功的 promise,然后,从第一个then(…)的成功回调函数中返回该 promise,这会使得第二个then(…)返回的 promise 在等待 2 秒后返回。
Note: Because a Promise is externally immutable once resolved, it’s now safe to pass that value around to any party, knowing that it cannot be modified accidentally or maliciously. This is especially true in relation to multiple parties observing the resolution of a Promise. It’s not possible for one party to affect another party’s ability to observe Promise resolution. Immutability may sound like an academic topic, but it’s actually one of the most fundamental and important aspects of Promise design, and shouldn’t be casually passed over.
注意:因为一个 promise 一旦解析其状态就不可以从外部改变,正是由于它的状态不可以被随意修改,所以可以安全地把状态值分发给任意第三方。当涉及多方观察 Promise 的返回结果时候更是如此。一方影响另一方观察 Promise 返回结果的能力是不可能。不可变性听起来像是个晦涩的科学课题,但是,实际上这是 Promise 最根本和重要的方面,你得好好研究研究。
To Promise or not to Promise?
Promise使用时机
An important detail about Promises is knowing for sure if some value is an actual Promise or not. In other words, is it a value that will behave like a Promise?
Promise 的一个重要细节即确定某些值是否是真正的 Promise。换句话说,这个值是否具有 Promise 的行为。
We know that Promises are constructed by the new Promise(…) syntax, and you might think that p instanceof Promise would be a sufficient check. Well, not quite.
我们知道可以利用
new Promise(…)语法来创建 Promise,然后,你会认为使用p instanceof Promise来检测某个对象是否是 Promise 类的实例。然而,并不全然如此。
Mainly because you can receive a Promise value from another browser window (e.g. iframe), which would have its own Promise, different from the one in the current window or frame, and that check would fail to identify the Promise instance.
主要的原因在于你可以从另一个浏览器窗口(比如 iframe)获得 Promise 实例,iframe 中的 Promise 不同于当前浏览器窗口或框架中的 Promise,因此,会导致检测 Promise 实例失败。
Moreover, a library or framework may choose to vend its own Promises and not use the native ES6 Promise implementation to do so. In fact, you may very well be using Promises with libraries in older browsers that have no Promise at all.
除此之外,库或框架或许会选择使用自身自带的 Promise 而不是原生的 ES6 实现的 Promise。实际工作中,你可以使用库自带的 Promise 来兼容不支持 Promise 的老版本浏览器。
Swallowing exceptions
异常捕获
If at any point in the creation of a Promise, or in the observation of its resolution, a JavaScript exception error occurs, such as a TypeError or ReferenceError, that exception will be caught, and it will force the Promise in question to become rejected.
如果在创建 Promise 或者是在观察解析 Promise 返回结果期间,遇到了诸如
TypeError或者ReferenceError的 JavaScript 错误异常,这个异常会被捕获进而强制 Promise 为失败状态。
For example:
比如
1 | var p = new Promise(function(resolve, reject){ |
But what happens if a Promise is fulfilled yet there was a JS exception error during the observation (in a then(…) registered callback)? Even though it won’t be lost, you may find the way they’re handled a bit surprising. Until you dig a little deeper:
但是,如果 Promise 成功解析了而在成功解析的监听函数(
then(…)注册回调)中抛出 JS 运行错误会怎么样?仍然可以捕捉到该异常,但或许你会发现处理这些异常的方式有些让人奇怪。直到深入理解其中原理:
1 | var p = new Promise( function(resolve,reject){ |
It looks like the exception from foo.bar() really did get swallowed. It wasn’t, though. There was something deeper that went wrong, however, which we failed to listen for. The p.then(…) call itself returns another promise, and it’s that promise that will be rejected with the TypeError exception.
看起来
foo.bar()抛出的错误异常真的被捕获到了。然而,事实上并没有。然而,深入理解你会发现我们没有监测到其中一些错误。p.then(…)调用本身返回另一个 promise,该 promise 会返回TypeError类型的异常失败信息。
非原文:
拓展一下以上的说明,这是原文没有的。
1 | var p = new Promise( function(resolve,reject){ |
如上代码所示就可以真正捕获到 promise 成功解析回调函数里面的代码错误。
Handling uncaught exceptions
处理未捕获的异常
There are other approaches which many would say are better.
有其它据说更好的处理异常的技巧。
A common suggestion is that Promises should have a done(…) added to them, which essentially marks the Promise chain as “done.” done(…) doesn’t create and return a Promise, so the callbacks passed to done(..) are obviously not wired up to report problems to a chained Promise that doesn’t exist.
普遍的做法是为 Promises 添加
done(..)回调,本质上这会标记 promise 链的状态为 “done.”。done(…)并不会创建和返回 promise,因此,当不存在链式 promise 的时候,传入done(..)的回调显然并不会抛出错误。
It’s treated as you might usually expect in uncaught error conditions: any exception inside a done(..) rejection handler would be thrown as a global uncaught error (in the developer console, basically):
和未捕获的错误状况一样:任何在
done(..)失败处理函数中的异常都将会被抛出为全局错误(基本上是在开发者控制台)。
1 | var p = Promise.resolve(374); |
What’s happening in ES8? Async/await
ES8中的Async/await
JavaScript ES8 introduced async/await that makes the job of working with Promises easier. We’ll briefly go through the possibilities async/await offers and how to leverage them to write async code.
JavaScript ES8 中介绍了
async/await,这使得处理 Promises 更加地容易。我们将会简要介绍async/await的所有可能的使用方式并利用其来书写异步代码。
How to use async/await?
如何使用 async/await
You define an asynchronous function using the async function declaration. Such functions return an AsyncFunction object. The AsyncFunction object represents the asynchronous function which executes the code, contained within that function.
使用
async函数定义一个异步函数。该函数会返回异步函数对象。AsyncFunction对象表示在异步函数中运行其内部代码。
When an async function is called, it returns a Promise . When the async function returns a value, that’s not a Promise , a Promise will be automatically created and it will be resolved with the returned value from the function. When the async function throws an exception, the Promise will be rejected with the thrown value.
当调用异步函数的时候,它会返回一个
Promise。异步函数返回值并非Promise,在函数执行过程中会自动创建一个Promise并使用函数的返回值来解析该Promise。当async函数抛出异常,Promise失败回调会获取抛出的异常值。
An async function can contain an await expression, that pauses the execution of the function and waits for the passed Promise’s resolution, and then resumes the async function’s execution and returns the resolved value.
async函数可以包含一个await表达式,这样就可以暂停函数的执行来等待传入的 Promise 的返回结果,之后重启异步函数的执行并返回解析值。
You can think of a Promise in JavaScript as the equivalent of Java’s Future or C#‘s Task.
你可以把 JavaScript 中的
Promise看作 Java 中的Future或C#中的 Task。The purpose of
async/awaitis to simplify the behavior of using promises.
async/await本意是用来简化 promises 的使用。
Let’s take a look at the following example:
看一下代码:
1 | // Just a standard JavaScript function |
Similarly, functions that are throwing exceptions are equivalent to functions that return promises that have been rejected:
类似地,抛出异常的函数等价于返回失败的 promises。
1 | function f1() { |
The await keyword can only be used in async functions and allows you to synchronously wait on a Promise. If we use promises outside of an async function, we’ll still have to use then callbacks:
await关键字只能在async函数中使用并且允许你同步等待 Promise。如果在async函数外使用 promises,我们仍然必须要使用then回调。
1 | async function loadData() { |
You can also define async functions using an “async function expression”. An async function expression is very similar to and has almost the same syntax as, an async function statement. The main difference between an async function expression and an async function statement is the function name, which can be omitted in async function expressions to create anonymous functions. An async function expression can be used as an IIFE (Immediately Invoked Function Expression) which runs as soon as it is defined.
你也可以使用异步函数表达式来定义异步函数。异步函数表达式拥有和异步函数语句相近的语法。异步函数表达式和异步函数语句的主要区别在于函数名,异步函数表达式可以忽略函数名来创建匿名函数。异步函数表达式可以被用作 IIFE(立即执行函数表达式),可以在定义的时候立即运行。
It looks like this:
像这样:
1 | var loadData = async function() { |
More importantly, async/await is supported in all major browsers:
更为重要的是,所有的主流浏览器都支持 async/await。

如果该兼容性不符合你的需求,你可以使用诸如 Babel 和 TypeScript 的 JS 转译器来转换为自己需要的兼容程度。
At the end of the day, the important thing is not to blindly choose the “latest” approach to writing async code. It’s essential to understand the internals of async JavaScript, learn why it’s so critical and comprehend in-depth the internals of the method you have chosen. Every approach has pros and cons as with everything else in programming.
最后要说的是,不要盲目地使用最新的技术来写异步代码。理解 JavaScript 中 async 的内部原理是非常重要的,学习为什么深入理解所选择的方法是很重要的。正如编程中的其它东西一样,每种技术都有其优缺点。
5 Tips on writing highly maintainable, non-brittle async code
书写高可用,强壮的异步代码的 5 条小技巧
Clean code: Using async/await allows you to write a lot less code. Every time you use async/await you skip a few unnecessary steps: write .then, create an anonymous function to handle the response, name the response from that callback e.g.
简洁:使用 async/await 可以让你写更少的代码。每次书写 async/await 代码,你都可以跳过书写一些不必要的步骤: 比如不用写
.then回调,创建匿名函数来处理返回值,命名回调返回值。
1 | // `rp` is a request-promise function. |
Versus:
对比
1 | // `rp` is a request-promise function. |
Error handling: Async/await makes it possible to handle both sync and async errors with the same code construct — the well-known try/catch statements. Let’s see how it looks with Promises:
错误处理:Async/await 允许使用日常的 try/catch 代码结构体来处理同步和异步错误。看下和 Promise 是如何写的:
1 | function loadData() { |
Versus:
1 | async function loadData() { |
Conditionals: Writing conditional code with async/await is a lot more straightforward:
条件语句:使用
async/await来书写条件语句会更加直观。
1 | function loadData() { |
Versus:
1 | async function loadData() { |
Stack Frames: Unlike with
async/await, the error stack returned from a promise chain gives no clue of where the error happened. Look at the following:堆栈桢:和
async/await不同的是,从链式 promise 返回的错误堆栈中无法得知发生错误的地方。看如下代码:
1 | function loadData() { |
Versus:
1 | async function loadData() { |
Debugging: If you have used promises, you know that debugging them is a nightmare. For example, if you set a breakpoint inside a .then block and use debug shortcuts like “stop-over”, the debugger will not move to the following .then because it only “steps” through synchronous code.
调试:如果使用 promise,你就会明白调试它们是一场噩梦。例如,如果你在 .then 代码块中设置一个断点并且使用诸如 “stop-over” 的调试快捷键,调试器不会移动到下一个 .then 代码块,因为调试器只会步进同步代码。
With async/await you can step through await calls exactly as if they were normal synchronous functions.
使用
async/await你可以就像同步代码那样步进到下一个 await 调用。




